Czym jest fine-tuning i jak go używać?
Modele językowe po pre-trainingu oferują szerokie możliwości, ale ich zastosowanie w konkretnych scenariuszach wymaga dopasowania do danych, procesów i sposobu interpretacji zapytań. W zależności od przypadku można to osiągnąć na poziomie zapytań, dostępu do wiedzy lub samego modelu. Fine-tuning dotyczy tego ostatniego obszaru i wiąże się z określonymi kosztami, ograniczeniami oraz zakresem zmian w jego działaniu.
Fine-tuning – na czym polega dostrajanie modelu i czym różni się od trenowania od zera?
Fine-tuning polega na dalszym trenowaniu modelu, który wcześniej został nauczony na dużych, ogólnych zbiorach danych. W tym etapie model nie uczy się od podstaw, lecz rozwija już istniejące reprezentacje języka i wiedzy, dopasowując je do konkretnego zadania lub kontekstu.
Różnica względem trenowania od zera (pre-trainingu) wynika przede wszystkim ze skali i celu procesu. Pre-training wymaga ogromnych zbiorów danych, dużej mocy obliczeniowej oraz uczenia wszystkich parametrów modelu od początku. Fine-tuning wykorzystuje gotowy model bazowy, dlatego koncentruje się na mniejszym, wyspecjalizowanym zbiorze danych i ingeruje tylko w wybrane elementy jego działania.
W wielu przypadkach oznacza to aktualizację części wag modelu przy jednoczesnym pozostawieniu niższych warstw bez zmian. Te warstwy odpowiadają za ogólne rozumienie języka, natomiast wyższe warstwy są dostosowywane do bardziej złożonych wzorców, takich jak styl odpowiedzi, struktura wypowiedzi czy interpretacja branżowych pojęć.
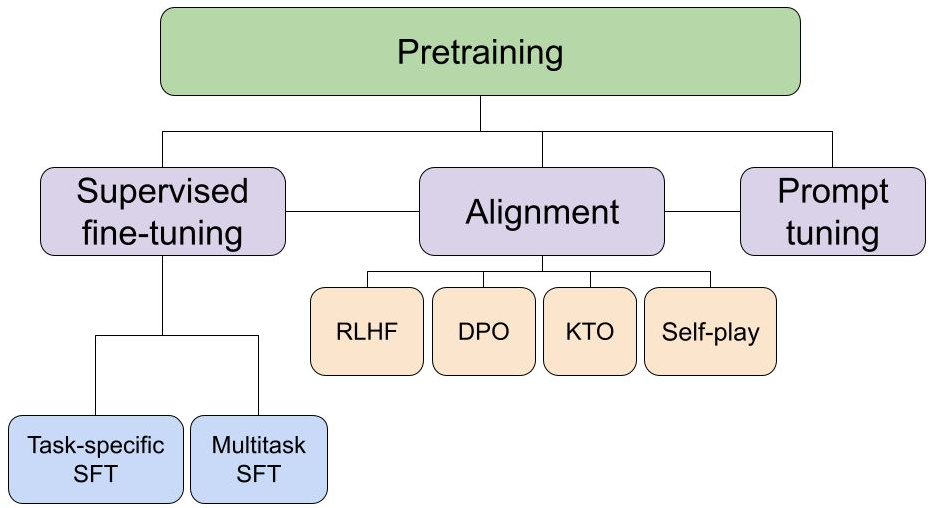
W zależności od podejścia fine-tuning może przyjmować różne formy. W supervised fine-tuning model uczy się na parach wejście–wyjście, co pozwala odwzorować oczekiwany sposób odpowiedzi. W metodach takich jak RLHF (Reinforcement Learning with Human Feedback) do procesu włączana jest ocena człowieka, która wpływa na preferowane odpowiedzi modelu.
Efektem jest model lepiej dopasowany do konkretnego zastosowania: rozumie węższy zakres pojęć, utrzymuje spójny sposób odpowiedzi i ogranicza błędy pojawiające się przy użyciu modelu ogólnego.
Kiedy fine-tuning ma sens, a kiedy wystarczy prompt engineering lub RAG?
Różnice między fine-tuningiem, prompt engineeringiem i RAG wynikają z tego, na jakim poziomie ingerują w działanie modelu. Każde z tych podejść rozwiązuje inny typ ograniczeń — od sposobu formułowania odpowiedzi, przez dostęp do danych, aż po utrwalenie zachowania modelu w powtarzalnych scenariuszach. Zestawienie tych podejść w jednym miejscu ułatwia określenie, gdzie faktycznie potrzebna jest zmiana.
| Podejście | Gdzie jest źródło problemu? | Najlepsze zastosowanie | Co zmieniasz w systemie | Przykłady danych/treści | Kiedy wdrażać? |
| Fine-tuning | W danych i w powtarzalnym, wąskim kontekście; potrzeba konsekwentnych decyzji i interpretacji | Utrwalenie sposobu interpretacji zapytań i formułowania odpowiedzi bez każdorazowego „naprowadzania” instrukcją | Parametry modelu (dostrajanie) | Specyficzne słownictwo, skróty wewnętrzne, jasno zdefiniowane procedury | Gdy po zastosowaniu prompt engineering i/lub RAG model nadal działa niespójnie, myli pojęcia lub nie utrzymuje schematu odpowiedzi w dużej skali |
| Prompt engineering | W sposobie odpowiedzi modelu (sterowanie zachowaniem na poziomie zapytania) | Narzucenie struktury odpowiedzi, tonu komunikacji i zakresu informacji; poprawa formatu odpowiedzi | Prompt/instrukcja (bez zmiany parametrów modelu) | Wymagany format odpowiedzi, styl/ton, zakres informacji | Często wystarcza na etapie wdrożenia; pozwala szybko ocenić jakość odpowiedzi |
| RAG | W dostępie do wiedzy: dane aktualne i rozproszone | Odpowiadanie na podstawie bieżących informacji dzięki dostarczaniu kontekstu z dokumentów | Dodatkowy kontekst (fragmenty dokumentów z bazy wiedzy), bez modyfikacji modelu | Regulaminy, cenniki, dokumentacja | Często wystarcza na etapie wdrożenia wraz z prompt engineering; dobre, gdy potrzebne są aktualne informacje bez „zapisywania” ich w parametrach modelu |
Podejścia te nie konkurują ze sobą, lecz działają na różnych warstwach systemu. Prompt engineering i RAG pozwalają kontrolować odpowiedzi bez ingerencji w parametry modelu, natomiast fine-tuning zmienia jego zachowanie w sposób trwały. Sens jego zastosowania pojawia się dopiero wtedy, gdy pozostałe metody nie zapewniają spójności działania w powtarzalnych scenariuszach.
Zastosowania fine-tuningu w obsłudze klienta, analizie danych i automatyzacji
Fine-tuning znajduje zastosowanie tam, gdzie model ma działać w powtarzalnych scenariuszach i utrzymywać spójny sposób interpretacji zapytań oraz formułowania odpowiedzi.
Jednym z takich obszarów jest obsługa klienta. Model dostrojony na historii rozmów i gotowych odpowiedziach przestaje generować ogólne komunikaty i zaczyna odpowiadać zgodnie z przyjętym schematem. Uwzględnia kolejność informacji, sposób prowadzenia rozmowy oraz warunki eskalacji, co ogranicza liczbę odpowiedzi wymagających korekty przez konsultanta.
Podobnie działa to w systemach klasyfikacji i routingu zgłoszeń. Fine-tuning pozwala przypisywać zapytania do konkretnych kategorii, priorytetów lub zespołów na podstawie wcześniej oznaczonych danych. Model nie tylko rozpoznaje temat zgłoszenia, ale także odwzorowuje sposób jego interpretacji przyjęty w organizacji.
W analizie dokumentów dostrojony model może wykrywać określone wzorce, takie jak naruszenia procedur, ryzyko prawne lub niespójności w treści. Zamiast ogólnej analizy pojawia się dopasowanie do konkretnego typu dokumentów i zasad ich oceny.
W zespołach technologicznych fine-tuning wykorzystywany jest do generowania kodu zgodnego z wewnętrznymi standardami. Model uczy się struktury projektów, konwencji nazewnictwa oraz sposobu implementacji, co ogranicza liczbę poprawek na etapie review.
Najważniejsze metody fine-tuningu modeli językowych
Metody fine-tuningu różnią się tym, które elementy modelu są modyfikowane oraz jak duży wpływ mają na jego działanie. Przekłada się to na różne poziomy kontroli, koszty oraz ryzyko przeuczenia.
Supervised fine-tuning (SFT)
Supervised Fine-Tuning (SFT) polega na trenowaniu modelu na przygotowanych parach wejście–wyjście, które odzwierciedlają oczekiwany sposób działania. Model uczy się nie tylko treści odpowiedzi, ale także ich struktury, kontekstu oraz sposobu interpretacji zapytań.
Takie podejście pozwala odwzorować konkretne wzorce językowe oraz schematy odpowiedzi charakterystyczne dla danej domeny. Model przestaje generować odpowiedzi ogólne i zaczyna działać zgodnie z przyjętym sposobem komunikacji.
SFT stanowi pierwszy etap dostrajania modelu i często poprzedza bardziej zaawansowane techniki, takie jak RLHF (Reinforcement Learning with Human Feedback). Na tym etapie model uczy się zależności między zapytaniem a odpowiedzią, które mogą być dalej optymalizowane.
Wprowadzenie SFT ogranicza błędy wynikające z niedopasowania modelu do kontekstu oraz wymaganego schematu odpowiedzi. Model odwzorowuje sposób interpretacji i reakcji, zapisany w danych treningowych, zamiast generować odpowiedzi na podstawie ogólnych wzorców językowych.
PEFT, LoRA i adaptery
PEFT (Parameter-Efficient Fine-Tuning) polega na dostrajaniu modelu bez modyfikowania wszystkich jego parametrów. Zamiast tego wprowadza się dodatkowe komponenty, takie jak adaptery lub mechanizmy LoRA, które odpowiadają za uczenie nowych zależności.
W podejściu LoRA (Low-Rank Adaptation) model rozszerzany jest o dodatkowe parametry o niskim wymiarze, które uczą się nowych zadań bez ingerencji w główne wagi modelu. Adaptery działają w podobny sposób, wprowadzając dodatkowe warstwy odpowiedzialne za dopasowanie modelu do specyficznych danych.
To podejście ogranicza zakres zmian w modelu i pozwala zachować jego pierwotne właściwości. Zmniejsza to ryzyko przeuczenia oraz utraty wcześniej nabytych umiejętności, co bywa problemem przy pełnym dostrajaniu.
PEFT sprawdza się tam, gdzie model wymaga częstych modyfikacji lub pracy na wielu wariantach danych. Umożliwia wprowadzanie zmian przy niższym koszcie obliczeniowym i bez konieczności ponownego trenowania całego modelu.
Pełny fine-tuning i dostrajanie wybranych warstw
Pełny fine-tuning polega na aktualizacji wszystkich wag modelu na nowych danych. Zapewnia maksymalną kontrolę nad jego zachowaniem i umożliwia dostosowanie do zadań, które wyraźnie odbiegają od rozkładu danych wykorzystanych w pre-trainingu. Wiąże się jednak z wysokim kosztem obliczeniowym oraz zwiększonym ryzykiem przeuczenia, wynikającym z ingerencji w całą przestrzeń parametrów modelu.
Alternatywą jest dostrajanie wybranych warstw. W tym podejściu niższe warstwy, odpowiedzialne za ogólne reprezentacje językowe, pozostają niezmienione, a aktualizowane są jedynie wyższe warstwy odpowiadające za bardziej złożone wzorce i zależności. Ogranicza to zakres modyfikacji i pozwala zachować wcześniej wyuczone właściwości modelu.
Różnica między tymi podejściami dotyczy głębokości ingerencji w architekturę modelu. Pełny fine-tuning umożliwia pełną adaptację kosztem zasobów i stabilności treningu. Dostrajanie warstw wprowadza zmiany selektywne, co pozwala lepiej kontrolować wpływ nowych danych na działanie modelu.
Jak przygotować dane do fine-tuningu i czego unikać na tym etapie?
Jakość danych bezpośrednio wpływa na efekt fine-tuningu, ponieważ model odwzorowuje wzorce obecne w zbiorze treningowym. Dane powinny odpowiadać rzeczywistym przypadkom, z którymi model będzie pracował, obejmując zapytania, dokumenty lub scenariusze związane z docelowym zastosowaniem.
Ważna jest zarówno ich różnorodność, jak i spójność. Zbyt jednorodny zbiór prowadzi do przeuczenia, natomiast dane niespójne utrudniają modelowi wypracowanie stabilnego schematu odpowiedzi. Równie ważna jest ich jakość. Błędy, duplikaty lub niejednoznaczne przykłady są bezpośrednio przenoszone do działania modelu.
Przed treningiem dane wymagają oczyszczenia i anonimizacji. Usunięcie informacji wrażliwych, takich jak dane osobowe lub numery identyfikacyjne, pozwala ograniczyć ryzyko naruszeń i zachować zgodność z regulacjami, w tym RODO.
Kolejnym etapem jest ujednolicenie formatu danych. W przypadku modeli językowych często stosuje się strukturę wejście–wyjście (prompt–completion), zapisaną w formacie JSONL. Taki zapis pozwala zachować spójność przykładów i ułatwia proces trenowania.
Dane powinny zostać podzielone na trzy zbiory: treningowy, walidacyjny i testowy. Zbiór treningowy odpowiada za naukę modelu, walidacyjny umożliwia kontrolę procesu i wykrywanie przeuczenia, a testowy służy do oceny jakości po zakończeniu treningu.
Najczęstsze problemy na tym etapie wynikają z niskiej jakości danych, ich powtarzalności lub braku dopasowania do rzeczywistego zadania.
Jak wygląda proces fine-tuningu?
Fine-tuning obejmuje kilka etapów, które prowadzą od wyboru modelu bazowego i przygotowania danych do testów oraz wdrożenia. Każdy z nich wpływa na końcowe działanie modelu i wymaga kontroli na poziomie jakości danych, konfiguracji treningu oraz oceny wyników.
Wybór modelu bazowego i zbioru danych
Modele trenowane na dużych zbiorach danych różnią się architekturą, jakością reprezentacji językowych oraz zakresem wiedzy, dlatego ich wcześniejsze wyniki w podobnych zadaniach stanowią istotny punkt odniesienia.
Rola danych na tym etapie polega nie tylko na ich jakości, ale przede wszystkim na dopasowaniu do konkretnego zastosowania. Zbiór treningowy powinien być dopasowany do sposobu użycia modelu oraz jego roli w procesie.
Ważne także jest dopasowanie skali oraz złożoności danych do możliwości modelu. Zbyt wymagający zestaw danych przy słabszym modelu prowadzi do niestabilnych wyników, natomiast prostsze przypadki przy bardziej zaawansowanym modelu nie wykorzystują jego potencjału.
Efektywność fine-tuningu wynika z dopasowania trzech elementów: modelu bazowego, danych oraz charakteru zadania. Brak spójności między nimi ogranicza wpływ treningu, niezależnie od jakości samego zbioru danych.
Ewaluacja, testy i wdrożenie
Po zakończeniu fine-tuningu model jest oceniany na danych, które nie były używane w procesie treningu. Pozwala to sprawdzić, czy odwzorował oczekiwane wzorce oraz jak radzi sobie z nowymi przypadkami.
Ewaluacja obejmuje zarówno metryki jakościowe, jak i analizę odpowiedzi w konkretnych scenariuszach. Na tym etapie identyfikowane są błędy interpretacji, niespójności oraz przypadki przeuczenia, które nie były widoczne podczas treningu.
Kolejnym krokiem są testy, które odwzorowują rzeczywiste użycie modelu. Ich celem jest sprawdzenie, czy model działa zgodnie z przyjętym schematem oraz czy utrzymuje spójność odpowiedzi w różnych kontekstach.
Na podstawie wyników podejmowana jest decyzja o wdrożeniu. Model trafia do środowiska produkcyjnego dopiero wtedy, gdy jego działanie jest przewidywalne i zgodne z wymaganiami zadania.
Wdrożenie nie zamyka procesu. Model wymaga ciągłego monitorowania, ponieważ zmiany w danych lub kontekście użycia mogą wpływać na jego działanie. Ważnym elementem jest także kontrola bezpieczeństwa i zgodności. Obejmuje to ochronę danych, ograniczanie ryzyka błędnych decyzji oraz nadzór nad sposobem generowania odpowiedzi w systemach mających wpływ na użytkownika.
Koszty, ograniczenia i ryzyka związane z fine-tuningiem
Fine-tuning wiąże się z szeregiem ograniczeń, które wynikają zarówno z charakteru modelu, jak i sposobu jego trenowania. Najczęściej dotyczą one kosztów, stabilności działania oraz pracy na danych.
- Koszty obliczeniowe. Fine-tuning wymaga dostępu do wydajnej infrastruktury, takiej jak GPU lub TPU, albo wykorzystania środowisk chmurowych. Przy dużych modelach przekłada się to bezpośrednio na koszt wdrożenia.
- Ryzyko przeuczenia. Model może zbyt silnie dopasować się do danych treningowych, co ogranicza jego zdolność do działania na nowych przypadkach i zawęża zakres jego zastosowania.
- Brak aktualizacji wiedzy. Po zakończeniu treningu model nie uwzględnia nowych informacji. Ma to znaczenie w obszarach, gdzie dane zmieniają się w czasie.
- Wpływ jakości danych. Błędy, niespójności lub nieaktualne informacje w zbiorze treningowym są bezpośrednio odwzorowywane w działaniu modelu, co utrudnia kontrolę jego odpowiedzi.
- Koszty utrzymania i aktualizacji. Model wymaga monitorowania, aktualizacji oraz dostosowania do zmieniającego się kontekstu użycia. W wielu przypadkach oznacza to konieczność ponownego dostrajania lub ograniczenia jego zakresu.
Jak ocenić, czy fine-tuning rzeczywiście poprawił działanie modelu?
Ocena efektów fine-tuningu opiera się na porównaniu działania modelu przed i po dostrojeniu na tym samym, niezależnym zbiorze danych. Pozwala to określić, czy model rzeczywiście poprawił sposób interpretacji zapytań i generowania odpowiedzi.
Analiza obejmuje zarówno metryki ilościowe, jak i ocenę jakości odpowiedzi. W przypadku klasyfikacji i zadań predykcyjnych stosuje się wskaźniki takie jak accuracy, precision, recall czy F1. W modelach generujących tekst dodatkowym punktem odniesienia mogą być metryki pokroju BLEU, choć ich interpretacja wymaga kontekstu zadania.
Same metryki nie oddają pełnego obrazu działania modelu. Uzupełnieniem są testy scenariuszowe, obejmujące typowe przypadki oraz sytuacje graniczne. Pozwalają one ocenić spójność odpowiedzi, stabilność działania oraz sposób reagowania modelu na mniej oczywiste zapytania.
Ocena powinna uwzględniać także wpływ modelu na procesy, w których jest wykorzystywany. Wskaźniki takie jak czas obsługi, liczba eskalacji czy konieczność korekty odpowiedzi pokazują, czy zmiany mają realne przełożenie na działanie systemu.
Brak poprawy lub pogorszenie wyników oznacza, że model nie odwzorował oczekiwanych zależności. W takich przypadkach konieczna jest ponowna analiza danych, konfiguracji treningu lub samego podejścia do dostrajania. Efektywność fine-tuningu wynika z relacji między jakością modelu a kosztem jego utrzymania. Poprawa wyników ma znaczenie tylko wtedy, gdy przekłada się na stabilne działanie modelu w docelowym zastosowaniu.
Żródła:
- https://biznesmysli.pl/fine-tuning-llm-fakty-i-mity/
- https://www.mdpi.com/2218-6581/13/5/68
- https://cameronrwolfe.substack.com/p/understanding-and-using-supervised
- https://cameronrwolfe.substack.com/p/easily-train-a-specialized-llm-peft
- https://digital.fabrity.com/blog/duze-modele-jezykowe-czym-sa-i-jak-dzialaja