Bezpieczeństwo i poufność danych w modelach językowych
Modele językowe, takie jak ChatGPT, Claude czy Gemini, coraz częściej wspierają działania biznesowe, edukacyjne czyjak i codzienne. Tworzą teksty, analizują dokumenty, wyjaśniają zagadnienia techniczne. Ich skuteczność opiera się na ogromnych zbiorach danych, które zostały wykorzystane podczas treningu. Jednocześnie korzystanie z takich modeli – zwłaszcza gdy wspierają codzienną pracę z klientami lub dokumentami firmowymi – rodzi pytania o to, co dzieje się z informacjami przekazywanymi podczas rozmowy i kto ponosi odpowiedzialność za ich bezpieczeństwo.
Pojawiają się wątpliwości, czy dane z rozmów mogą być wykorzystywane do dalszego uczenia modeli, czy są zapamiętywane, a jeśli tak – to na jak długo i przez kogo. Do tego dochodzi problem zgodności z RODO, brak przejrzystości w politykach prywatności, ryzyko ataków typu prompt injection czy nieświadomego ujawnienia danych wrażliwych. Dla osób i firm, które korzystają z narzędzi opartych na LLM, ważne staje się zrozumienie, jakie informacje mogą być przetwarzane, jak działają zabezpieczenia oraz na co zwracać uwagę przy wdrażaniu tych narzędzi w pracy.
Jak działają modele językowe i gdzie przechowywane są dane użytkownika?
Modele językowe nie działają jak wyszukiwarki i nie pobierają odpowiedzi z internetu wprost. Generują je na podstawie wzorców językowych, które zostały zapamiętane w trakcie treningu na miliardach przykładów tekstów. To przewidywanie kolejnego słowa w zdaniu na podstawie rozkładów prawdopodobieństwa, a nie pobieranie gotowej treści. W nowszych rozwiązaniach modele bywają jednak łączone z dodatkowymi warstwami, które dają im dostęp do aktualnych źródeł. Przykładem są funkcje takie jak Deep Research w ChatGPT, integracje w Google Gemini czy metody RAG (Retrieval-Augmented Generation). W takich przypadkach model nadal działa statystycznie, ale równocześnie korzysta z danych pobranych w czasie rzeczywistym z wyszukiwarki lub zewnętrznych baz wiedzy.
Etap uczenia modelu to proces złożony i przeprowadzany niezależnie od codziennego użytkowania. W jego trakcie system analizuje ogromne zbiory tekstów, by wyłapać wzorce i nauczyć się tworzenia logicznych, spójnych wypowiedzi. W tej fazie nie zapamiętuje jednak konkretnych dokumentów czy osób – zapamiętuje jedynie struktury językowe, rozkłady prawdopodobieństw i ogólne zależności między słowami. Po zakończeniu treningu model nie wie, skąd pochodzi dana informacja ani jak ją zweryfikować – nie ma dostępu do źródeł.
Dane wpisywane w trakcie użytkowania przetwarzane są osobno – i tymczasowo. Mogą być wykorzystywane do poprawy jakości usług, testowania funkcji lub wykrywania nadużyć, ale nie trafiają automatycznie do ponownego treningu. Często dostępna jest opcja wyłączenia historii rozmów lub pracy w trybie, który izoluje dane od dalszego przetwarzania. Zasady te zależą bezpośrednio od dostawcy i warto je dokładnie sprawdzić przed użyciem systemu.
Najważniejsze jest rozróżnienie między uczeniem modelu (co dzieje się raz, na dużej skali) a codziennym przetwarzaniem danych w trakcie użytkowania. Oba procesy rządzą się innymi regułami – i mają inne konsekwencje dla prywatności.
Czy LLM zapamiętują, co piszesz?
Wiele osób zakłada, że rozmowy z modelem językowym są jednorazowe i ulotne. Po zamknięciu okna wszystko znika. To częściowo prawda, ale wiele zależy od konfiguracji narzędzia i polityki przyjętej przez dostawcę. W typowych zastosowaniach dane z jednej sesji nie są zapisywane na stałe ani wykorzystywane do ponownego treningu modelu. Zdarzają się jednak wyjątki.
Treści wpisywane przez użytkownika mogą być tymczasowo przechowywane na serwerach operatora systemu. Często służą do testowania funkcji, poprawy jakości działania albo wykrywania nadużyć. Jeśli historia czatu nie zostanie ręcznie wyłączona, model może wykorzystywać te dane wewnętrznie. Niektóre platformy dają pełną kontrolę nad tym procesem, inne wymagają zastosowania wersji płatnej lub firmowej.
Brak kontroli nad domyślnymi ustawieniami potrafi prowadzić do poważnych problemów. Przykładem jest sprawa firmy Samsung. Pracownicy działu półprzewodników przesłali do modelu fragmenty kodu źródłowego i dane testowe. Miało to usprawnić pracę, ale z powodu aktywnej historii czatu informacje trafiły do analizy systemowej. Choć nie zostały publicznie ujawnione, samo ich wyniesienie poza infrastrukturę uznano za poważne naruszenie. W efekcie Samsung całkowicie zakazał używania publicznych narzędzi AI przez pracowników.
Dodatkowe ryzyko dotyczy integracji z zewnętrznymi usługami. Przykładem są pluginy, aplikacje API albo funkcje współdzielenia czatu. W takich przypadkach dane mogą trafiać do innych systemów, których polityka prywatności nie jest znana użytkownikowi końcowemu. Z tego powodu każda organizacja wdrażająca modele językowe powinna jasno określić, jak dane są przetwarzane, kto ma do nich dostęp i jakie ustawienia są domyślnie aktywne.
Jakie dane są przetwarzane i jakie niesie to ryzyko?
Oprócz treści rozmowy modele mogą przetwarzać dane kontekstowe, takie jak lokalizacja, adres IP, typ przeglądarki, czas sesji czy aktywność w interfejsie. Część platform rejestruje też dane telemetryczne, w tym sposób przewijania, kliknięcia lub zmiany ustawień.
Największym zagrożeniem pozostaje to, co użytkownik wpisuje samodzielnie. Modele nie rozpoznają danych poufnych i traktują je jak każdy inny tekst. Wprowadzenie numerów PESEL, danych klientów, haseł lub informacji projektowych nie uruchamia żadnych filtrów ani ostrzeżeń. Taka treść może zostać tymczasowo zapisana i wykorzystana do testów lub analizy jakości, jeśli użytkownik nie zmieni ustawień prywatności.
Modele językowe potrafią łączyć fragmenty rozmów w spójny obraz. Nawet pozornie neutralne informacje, jak lokalizacja czy stanowisko, mogą posłużyć do odtworzenia pełnego profilu użytkownika. W badaniach „Privacy Risks of LLM-Empowered Recommender Systems: An Inversion Attack Perspective”, przeprowadzonych przez zespół naukowców z Hong Kong Polytechnic University, Zhejiang University, Singapore Management University oraz AI Singapore, wykazano, że możliwe jest odtworzenie znaczących fragmentów historii działań użytkownika oraz jego preferencji na podstawie pozornie neutralnych danych wejściowych. W testach opisanych w publikacji skuteczność rekonstrukcji treści przekroczyła 85%, a dopasowanie profilu użytkownika sięgnęło 87%. Autorzy podkreślają, że nawet jeśli użytkownik nie podaje wprost wrażliwych danych, model może „złożyć” je z drobnych informacji rozproszonych w różnych interakcjach.
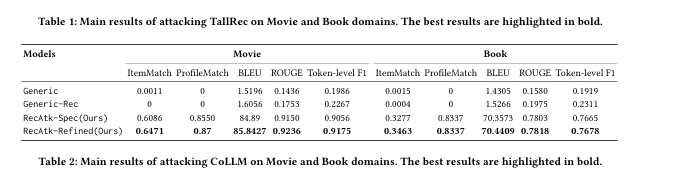

Ryzyko dotyczy także infrastruktury technicznej. Dane są przesyłane do chmury i mogą być przetwarzane w ramach testów A/B, logów lub automatycznych analiz. Ataki na serwery, błędy konfiguracji lub niewłaściwe zarządzanie dostępem to realne wektory wycieku.
RODO i prawo – kto odpowiada za dane w LLM?
Ważnym pytaniem prawnym przy korzystaniu z modeli językowych jest to, kto pełni rolę administratora danych. To określenie decyduje, na kim spoczywa obowiązek zapewnienia zgodności z RODO i kto odpowiada za realizację praw użytkownika, takich jak prawo do usunięcia danych czy dostęp do informacji.
Stanowiska organów nadzoru nie są jednolite. Komisarz ds. ochrony danych w Hamburgu uznaje, że w niektórych przypadkach odpowiedzialność powinna spoczywać na podmiotach wdrażających model, czyli użytkownikach. Taka interpretacja oznaczałaby, że firmy korzystające z narzędzi opartych na LLM musiałyby obsługiwać wnioski RODO samodzielnie, nawet jeśli nie mają kontroli nad modelem.

Z kolei Europejska Rada Ochrony Danych (EROD) stoi na stanowisku przeciwnym. Wskazuje, że obowiązków nie można przenosić na użytkowników końcowych, a pełną odpowiedzialność ponosi dostawca systemu. Argument opiera się na zasadzie uczciwości – jeśli użytkownik ma ograniczony wpływ na przetwarzanie danych, nie może być uznany za ich administratora. To podejście chroni spójność systemu ochrony danych w Unii Europejskiej i ogranicza ryzyko przerzucania odpowiedzialności na osoby fizyczne lub organizacje nieposiadające zaplecza prawnego.

Spór ten przypomina debatę z czasów rozwoju mediów społecznościowych. Wówczas również próbowano wskazywać użytkowników jako administratorów, ale Grupa Robocza Art. 29 uznała, że faktyczna kontrola nad danymi spoczywa na dostawcach platform. Ten precedens stał się fundamentem aktualnej interpretacji stosowanej także wobec LLM.
Oprócz RODO w Unii Europejskiej zaczyna obowiązywać także AI Act (rozporządzenie 2024/1689). Weszło w życie 1 sierpnia 2024, a przepisy wdrażane są etapami do 2026 roku. Od lutego 2025 roku wymagane jest zapewnianie tzw. AI literacy, czyli szkoleń z obsługi i rozumienia systemów AI. Od sierpnia 2025 dostawcy modeli ogólnego przeznaczenia (GPAI) muszą spełniać dodatkowe obowiązki związane z transparentnością i dokumentacją, w tym informować użytkowników, czy ich dane mogą być wykorzystywane do dalszego trenowania. Nadzór nad zgodnością sprawuje European AI Office wraz z AI Board. Naruszenia mogą skutkować karami finansowymi sięgającymi 6% globalnego obrotu lub 35 mln euro.


Istnieje również wyjątek od stosowania RODO w przypadku działań czysto osobistych. Nie obejmuje on jednak sytuacji, w których dane są przetwarzane za pośrednictwem narzędzi publicznych, a ich zasięg wykracza poza prywatny użytek. Gdy model jest dostępny publicznie, a jego operator zbiera dane użytkowników, obowiązki wynikające z RODO mają zastosowanie w pełnym zakresie.
Transparentność dostawców – co ujawniają firmy o sposobie uczenia modeli?
Sposób, w jaki dostawcy modeli językowych przetwarzają dane, różni się w zależności od platformy. Polityki prywatności i dokumentacja techniczna to jedyne oficjalne źródła, które pozwalają ocenić, czy treści rozmów są wykorzystywane do dalszego treningu, jak długo są przechowywane i jakie mechanizmy ochrony są stosowane.
Porównanie zasad przetwarzania danych przez dostawców LLM
| Kryterium / Dostawca | OpenAI (ChatGPT) | Anthropic (Claude) | Google (Gemini / NotebookLM) |
| Administrator danych w UE | OpenAI Ireland Limited | Spółka Anthropic w UE (RODO) | Google Ireland Limited |
| Zakres gromadzonych danych | Treści rozmów (prompty, pliki, obrazy, audio), dane techniczne: IP, urządzenie, lokalizacja | Treści rozmów, załączniki, dane techniczne: IP, urządzenie, przeglądarka, lokalizacja | Treści wprowadzane w czacie lub dokumencie, przesyłane pliki, dane techniczne: IP, urządzenie, lokalizacja, aktywność |
| Trenowanie modeli | W wersji standardowej możliwe, opcja opt-out; w Enterprise brak treningu | Brak domyślnego treningu, opt-in; w API zero-retention na żądanie | W Gemini dane z rozmów mogą być używane do trenowania, ale w trybach Workspace/NotebookLM brak treningu na danych użytkownika |
| Czas przechowywania rozmów | Do 30 dni dla rozmów tymczasowych | Do 30 dni; opcja natychmiastowego usunięcia historii | Historia konwersacji w Gemini przechowywana domyślnie, w NotebookLM dokumenty przechowywane do momentu usunięcia przez użytkownika |
| Udostępnianie danych podwykonawcom | Tak – usługi chmurowe, bezpieczeństwo, obsługa klienta | Tak – zaufani dostawcy usług technicznych i bezpieczeństwa | Tak – podmioty przetwarzające dane w ramach Google Cloud i Workspace |
| Bezpieczeństwo i certyfikaty | Szyfrowanie AES256 i TLS 1.2+, zgodność SOC 2, SAML SSO | Szyfrowanie w tranzycie i spoczynku, ograniczony dostęp Trust & Safety | Szyfrowanie w tranzycie i spoczynku, zgodność z normami Google Cloud, mechanizmy IAM |
| Tryby biznesowe | Enterprise, Team, API – klient właścicielem danych, pełna kontrola retencji | Szyfrowanie w tranzycie i spoczynku, ograniczony dostęp Trust & Safety | Szyfrowanie w tranzycie i spoczynku, zgodność z normami Google Cloud, mechanizmy IAM |
Czego nie wpisywać podczas rozmów z chatbotem?
Do szczególnie ryzykownych danych należą:
- dane identyfikacyjne, np. PESEL, numery dowodów i paszportów,
- dane finansowe, np. numery kart, kont bankowych, kody CVV,
- dane logowania, hasła, tokeny API,
- poufne informacje biznesowe, np. kody źródłowe, dokumentacja projektowa, strategie sprzedażowe,
- dane osobowe klientów i pracowników, np. adresy e-mail, telefony, adresy zamieszkania,
- informacje medyczne lub objęte tajemnicą zawodową.
Jak już zaznaczaliśmy, nawet fragmentaryczne informacje mogą zostać połączone w spójny obraz użytkownika lub organizacji.
Ryzyko ataków typu prompt injection
Atak typu prompt injection polega na wprowadzeniu do modelu językowego treści, która manipuluje jego działaniem. Może to być komenda ukryta w tekście, pliku lub obrazie, która nakłania model do ujawnienia poufnych danych, wykonania nieautoryzowanej czynności lub zignorowania dotychczasowych instrukcji. Tego rodzaju ataki są szczególnie groźne w środowisku firmowym, gdzie chatbot może mieć dostęp do dokumentów, systemów lub narzędzi wewnętrznych. Prompt injection może przybrać różne formy:
- instrukcje nakłaniające model do ujawnienia informacji, do których nie powinien mieć dostępu,
- wprowadzenie polecenia usuwającego lub zmieniającego dane,
- wstrzyknięcie szkodliwego kodu w treści przekazywanej modelowi,
- tworzenie fałszywego kontekstu rozmowy, aby zmylić model.
Ryzyko rośnie, gdy model działa w zintegrowanym środowisku, np. z bazami danych, systemami CRM czy narzędziami do automatyzacji procesów.
Jak się przed tym bronić?
Najprostsze i najskuteczniejsze działania to wyłączenie historii rozmów i korzystanie z trybów, w których dane nie trafiają do treningu modeli. Warto wprowadzać wyłącznie informacje niezbędne do realizacji zadania, zastępując dane wrażliwe przykładami lub wersjami testowymi. Każdy plik i treść przekazywana do modelu powinny pochodzić z zaufanego źródła, aby uniknąć prób wstrzyknięcia szkodliwych poleceń. Pomagają też filtry i monitoring, które wykrywają nietypowe zachowania modelu. Ważne jest regularne szkolenie pracowników w zakresie rozpoznawania danych poufnych i stosowania zasad bezpieczeństwa.
Zasady korzystania z LLM w środowisku firmowym
Wdrożenie modeli językowych w firmie powinno iść w parze z jasnymi zasadami ich obsługi. Warto określić, jakie dane można wprowadzać do czatu, a jakie muszą pozostać poza nim. Ustawienia prywatności powinny być skonfigurowane tak, by rozmowy nie były zapisywane ani używane do trenowania modeli. Najbezpieczniej korzystać z wersji narzędzi przeznaczonych do pracy zespołowej, takich jak tryby Enterprise, Workspace czy API z zerową retencją, i logować się wyłącznie na kontach firmowych. Dostęp do narzędzi warto ograniczyć do osób przeszkolonych, które znają procedury ochrony danych. Silne uwierzytelnianie, np. w modelu SSO, oraz regularne przeglądy ustawień i logów pozwolą wychwycić ewentualne nieprawidłowości. Takie podejście minimalizuje ryzyko i pozwala w pełni korzystać z możliwości LLM bez narażania poufnych informacji.