Jak działają tokeny w AI i dlaczego wpływają na koszty korzystania z modeli językowych?
Rosnąca liczba zastosowań sztucznej inteligencji pokazuje, że technologia rozwija się w tempie niespotykanym w innych dziedzinach. Według raportu Stanford HAI, prawie 90% znaczących modeli AI powstało w 2024 roku w sektorze przemysłowym, podczas gdy rok wcześniej było to 60%. Korzystając z modeli językowych, odczuwasz rozwój sztucznej inteligencji bezpośrednio – właśnie poprzez tokeny, które są podstawą działania i rozliczeń systemów AI.
Token – najmniejsza jednostka językowa w świecie AI
Modele językowe muszą radzić sobie z językami o różnej strukturze, ze złożonymi formami fleksyjnymi, skrótami, symbolami i znakami specjalnymi. Dlatego tekst nie jest dzielony na słowa, ale na mniejsze elementy.
Tokenem może być:
- całe słowo w języku polskim, jeżeli występuje często i znajduje się w podstawowym słowniku modelu;
- fragment dłuższego wyrazu, na przykład przyrostek, rdzeń albo początek słowa;
- pojedynczy znak, litera, cyfra lub symbol interpunkcyjny;
- spacja oddzielająca wyrazy.
Taki podział sprawia, że model jest elastyczny i potrafi „zrozumieć” zarówno popularne słowa, jak i bardzo rzadkie połączenia liter. Z punktu widzenia użytkownika liczy się jednak przede wszystkim fakt, że każdy token zużywa część zasobów.
Jak modele dzielą tekst na tokeny?
Podział na tokeny nie odbywa się ręcznie. Modele językowe stosują algorytmy segmentacji oparte na statystyce. Jednym z popularnych podejść jest tzw. segmentacja podciągów. Polega na tym, że najczęściej używane ciągi znaków zachowywane są w całości, a rzadsze wyrazy rozbijane są na mniejsze fragmenty.
Przykład:
- słowo „dom” może być zapisane jako jeden token,
- rzadkie słowo „bezprzewodowy” zostanie rozbite na kilka tokenów, np. „bez”, „przewod”, „owy”.
Taki system sprawia, że model uczy się szybko, a przy tym nie wymaga zapamiętania całego słownika języka.
Liczenie tokenów
Skoro każdy token zajmuje część zasobów, konieczne było stworzenie metody dokładnego liczenia.
W praktyce działa to tak, że:
- każde pytanie od użytkownika zostaje zamienione na określoną liczbę tokenów;
- odpowiedź modelu również jest rozbita na tokeny;
- suma obu wartości stanowi podstawę do naliczenia opłaty.
Wyobraź sobie krótkie pytanie: „Jaka jest stolica Francji?”. W podziale na tokeny wygląda to mniej więcej tak: „Jaka”, „jest”, „stolica”, „Francji”, „?”. Odpowiedź „Paryż” to kolejny token.
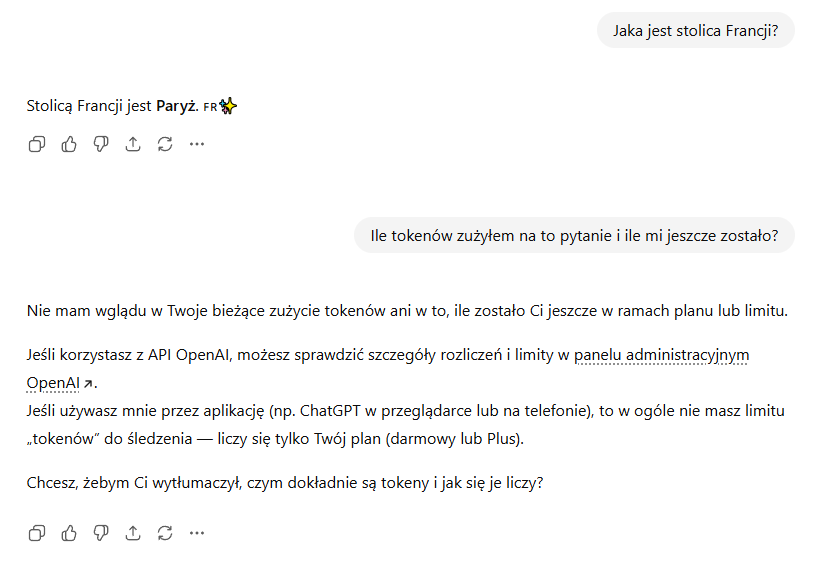
Informacja na temat tokenów od ChatGPT.
Tokeny a koszty – skąd bierze się rachunek?
Firmy udostępniające modele nie rozliczają Cię za pytania w klasycznym sensie. Cena wynika z liczby przetworzonych tokenów. Krótka konwersacja jest tania, natomiast rozbudowany raport lub analiza dokumentów wymaga tysięcy tokenów i staje się kosztowna.
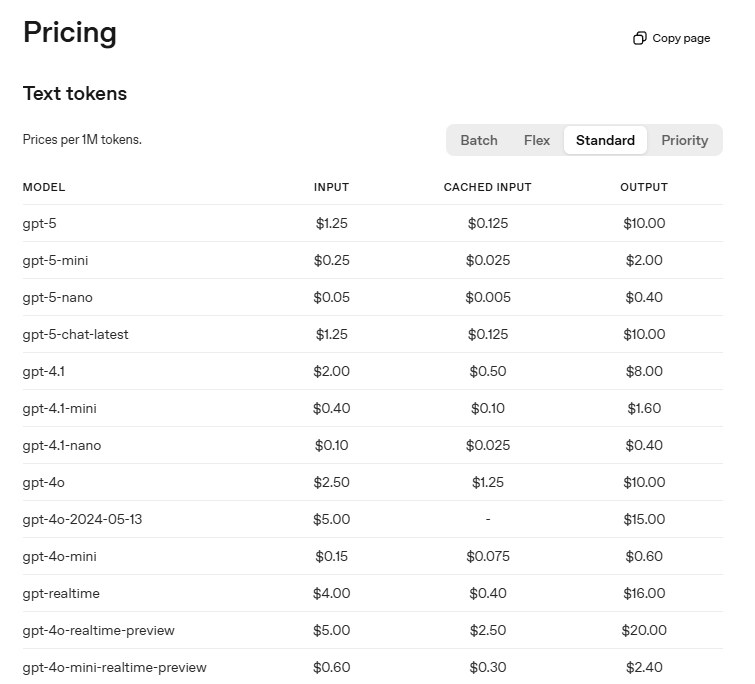
Cena za milion tokenów w ChatGPT.
Dlaczego liczba tokenów wpływa na wydajność?
Modele językowe działają na zasadzie sekwencyjnego przetwarzania. Każdy token jest analizowany w kontekście poprzednich. Im dłuższy kontekst, tym więcej obliczeń musi wykonać system.
W praktyce prowadzi to do kilku zjawisk:
- dłuższy czas odpowiedzi przy dużych tekstach;
- większe zużycie energii elektrycznej w centrach danych;
- rosnące koszty utrzymania serwerów;
- konieczność ograniczania długości zapytań i odpowiedzi;
- wyraźny wpływ na jakość działania modeli w sytuacjach, gdy kontekst przekracza dopuszczalny limit.
Przykład: GPT-3 miał limit 4096 tokenów, co wystarczało na kilka stron tekstu. Rozszerzona wersja GPT-4 obsługuje nawet 32 tysiące tokenów, a w eksperymentalnych wersjach mówi się o 128 tysiącach. To już całe rozdziały książek, ale koszty takiej analizy są nieporównywalnie wyższe.
Granice i limity tokenów
Każdy model ma określony maksymalny kontekst, czyli maksymalną liczbę tokenów, które może przetworzyć w jednej sesji. Jeżeli przekroczysz ten limit, część informacji zostaje obcięta. To wpływa na jakość odpowiedzi, ale również na sposób, w jaki planujesz korzystanie z narzędzia.
Dlatego w pracy z modelami istotne jest świadome zarządzanie długością zapytań i odpowiedzi. Firmy często optymalizują dokumenty przed ich wprowadzeniem do systemu, aby zmieścić się w limicie tokenów i zminimalizować koszt.
Informacje na temat granic ChatGPT Plus.
Świadome korzystanie z tokenów
Kiedy już rozumiesz, że tokeny są jednostką rozliczeniową, możesz inaczej spojrzeć na swoje interakcje z modelem. W każdej sesji pojawia się pytanie: jak napisać zapytanie, żeby było skuteczne, a jednocześnie nie generowało niepotrzebnych kosztów?
To kwestia planowania. Modele nie potrzebują ozdobników stylistycznych w pytaniach. Nie musisz pisać „bardzo proszę, czy mogłabyś mi pomóc znaleźć informacje na temat…”. Wystarczy jasna, zwięzła treść. Każde dodatkowe słowo to dodatkowy token.
Najczęstsze błędy użytkowników pod kątem wykorzystywania narzędzi AI
Najpopularniejsze błędy w zakresie wykorzystywania narzędzi AI:
- rozwlekłe pytania – im dłuższa forma, tym większa liczba tokenów i wyższy koszt;
- powtarzanie tych samych fragmentów tekstu w wielu zapytaniach – zamiast podać kontekst raz, wklejają go przy każdej interakcji;
- niekontrolowane generowanie bardzo długich odpowiedzi, które pochłaniają tysiące tokenów;
- brak skracania dokumentów przed ich analizą przez model – pełne raporty trafiają w całości, mimo że użytkownik potrzebuje tylko fragmentu;
- ignorowanie limitów kontekstu, przez co część danych zostaje ucięta, a wyniki stają się niepełne.
Strategie ograniczania kosztów – jak zużywać mniej tokenów, nie tracąc jakości w odpowiedziach?
Spośród sprawdzonych sposobów wyróżniamy:
Zwięzłość w pytaniach
Modele lepiej radzą sobie z prostymi, konkretnymi poleceniami. Unikaj nadmiarowych opisów i zbędnych wstępów.
Dzielenie dokumentów
Zamiast wrzucać setki stron na raz, podziel materiał na mniejsze części. Analizując je stopniowo, oszczędzasz zasoby i zachowujesz kontrolę nad kosztem.
Ustalanie długości odpowiedzi
W wielu przypadkach możesz określić, że chcesz, aby model udzielił krótszej odpowiedzi. Wystarczy zaznaczyć, że oczekujesz streszczenia, kilku punktów lub konkretnego akapitu.
Kompresja kontekstu
Zamiast przesyłać pełne dane przy każdym pytaniu, rekomendujemy wcześniej stworzyć ich streszczenie. Krótszy kontekst oznacza mniej tokenów.
Automatyzacja procesów
Firmy coraz częściej wykorzystują narzędzia, które automatycznie skracają i porządkują treści przed wysłaniem ich do modelu. To praktyka pozwalająca obniżyć koszty o kilkadziesiąt procent.
Świadomość tych różnic jest niezbędna, jeśli planujesz pracę na poważnie.
Przykłady realnych zastosowań sztucznej inteligencji w codziennej praktyce
W pierwszej kolejności należy wspomnieć o kancelariach, które coraz częściej korzystają z modeli do przeszukiwania i streszczania dokumentów. Przetworzenie wielostronicowej umowy oznacza dziesiątki tysięcy tokenów. W takim przypadku każdy skrót czy streszczenie przed analizą przekłada się na wymierne oszczędności.
Badania naukowe
Naukowcy wykorzystują modele do analizy literatury i raportów. Artykuły liczące po 10–15 stron generują tysiące tokenów. Przy setkach tekstów koszty szybko rosną, dlatego stosuje się wstępne podsumowania.
Media i redakcje
Dziennikarze używają AI do tworzenia zarysów artykułów czy sprawdzania faktów. W tym przypadku tokeny rzadko liczone są pojedynczo, ale przy produkcji kilkudziesięciu materiałów dziennie całkowity rachunek staje się odczuwalny.
Branża technologiczna
Firmy IT wykorzystują modele do analizy kodu źródłowego. Każda linijka kodu to kolejne tokeny, a przy setkach tysięcy linii koszty mogą być znaczące.
Dodatkowy cennik tokenów w ChatGPT dla branży technologicznej.
Czy tokeny pozostaną podstawową jednostką rozliczeń?
Obecny system opiera się na tokenach, ponieważ są one praktycznym miernikiem pracy modelu. Łatwo je liczyć, a przy tym dobrze oddają faktyczne obciążenie obliczeniowe. Jednak rynek sztucznej inteligencji zmienia się błyskawicznie. Firmy szukają rozwiązań, które uproszczą rozliczenia i sprawią, że korzystanie z AI będzie jeszcze bardziej przewidywalne. Na horyzoncie widać kilka możliwych kierunków rozwoju systemów rozliczeń:
- rozliczenia za czas korzystania – użytkownik płaci za minuty lub godziny pracy modelu, niezależnie od liczby tokenów;
- abonamenty ryczałtowe – stała opłata miesięczna, obejmująca określony limit zapytań lub pełny dostęp bez ograniczeń;
- rozliczenia za konkretne zadania – cena ustalana w zależności od typu zadania, np. streszczenie artykułu, analiza kodu, tłumaczenie tekstu;
- modele hybrydowe – połączenie abonamentu z dodatkową opłatą za nadmiarowe tokeny;
- dynamiczne taryfy – zmienne ceny w zależności od obciążenia serwerów i pory dnia.
Każde z tych podejść ma swoje zalety i wady. Tokeny nadal pozostają najbardziej precyzyjne, ale mogą być dla użytkownika zbyt skomplikowane w codziennym rozliczaniu.
Wpływ rosnącej mocy obliczeniowej
Modele stają się coraz większe, a ich limity kontekstu zwiększają się z kilku tysięcy do dziesiątek, a nawet setek tysięcy tokenów. GPT-4 w wersji eksperymentalnej potrafił już analizować teksty odpowiadające objętością kilkudziesięciu stron książki.
Rosnąca moc obliczeniowa otwiera nowe możliwości, m.in.:
- analiza pełnych raportów bez dzielenia na fragmenty;
- praca z dużymi bazami danych tekstowych;
- tworzenie wieloetapowych odpowiedzi wymagających pamięci kontekstowej.
Jednak większa moc oznacza również większe zużycie energii i wyższe koszty utrzymania infrastruktury. Dlatego firmy prawdopodobnie będą wprowadzać nowe formy rozliczeń, aby utrzymać równowagę między dostępnością a rentownością.
Tokeny a personalizacja modeli
Coraz częściej mówi się o dostosowywaniu modeli do potrzeb konkretnych firm czy użytkowników. W takim scenariuszu tokeny nabierają nowego znaczenia.
Przykładowo:
- firma prawnicza trenuje model na własnych dokumentach i potrzebuje analizy długich umów,
- wydawnictwo pracuje nad generowaniem streszczeń książek,
- instytucja badawcza wykorzystuje AI do przetwarzania artykułów naukowych.
W każdym przypadku tokeny stają się nie tylko kosztem, ale też narzędziem planowania. To jednostka, którą można przewidzieć, zmierzyć i uwzględnić w strategii działania.
Przyszłość a użytkownik indywidualny
Dla osób korzystających z modeli na co dzień – w pracy, edukacji czy rozrywce – tokeny mogą wkrótce zejść na dalszy plan. Firmy będą starały się ukrywać je za prostszymi formami rozliczeń, tak aby użytkownik płacił np. abonament miesięczny bez konieczności liczenia każdej jednostki (np. w postaci maksymalnej liczby wiadomości w konkretnym czasie, np. trzech godzin).
Tokeny a transparentność
Z drugiej strony, wielu ekspertów podkreśla, że całkowite odejście od tokenów może obniżyć przejrzystość. Dziś wiesz dokładnie, za co płacisz: liczba tokenów = wysokość rachunku. Przy systemie abonamentowym trudniej zrozumieć, gdzie kryją się realne koszty.
Dlatego możliwe, że tokeny pozostaną w tle – jako jednostka techniczna – nawet jeśli użytkownik końcowy nie będzie musiał ich świadomie liczyć.
Wnioski
Tokeny stanowią podstawową jednostkę rozliczeniową w modelach językowych, a ich liczba wpływa zarówno na koszty, jak i wydajność systemu. Rozumiejąc mechanizmy segmentacji i limity kontekstu, możesz skuteczniej planować pracę i minimalizować zużycie zasobów. Warto również wspomnieć, iż świadome zarządzanie tokenami oznacza bardziej precyzyjne pytania, mniejsze obciążenie obliczeniowe i bardziej przewidywalne koszty. W konsekwencji zyskujesz kontrolę nad efektywnością korzystania z narzędzi AI.
Tokeny w AI – FAQ
Jakie są najczęstsze pytania i odpowiedzi na temat tokenów w AI?
Czym dokładnie jest token w modelach językowych?
Token to najmniejsza jednostka tekstu rozpoznawana przez model. Może obejmować całe słowo, fragment wyrazu, pojedynczy znak interpunkcyjny albo spację.
Dlaczego liczba tokenów wpływa na koszty korzystania z AI?
Każdy token oznacza dodatkowe obliczenia w sieci neuronowej, przekładając się na większe zużycie zasobów i wyższą cenę. Im dłuższe zapytanie i odpowiedź, tym większy rachunek.
Jak mogę zmniejszyć liczbę tokenów?
Pisząc krótsze pytania, dzieląc dokumenty na fragmenty oraz prosząc o streszczenia zamiast pełnych tekstów. Takie podejście redukuje obciążenie i poprawia efektywność kosztową.
Czy limity tokenów różnią się między modelami?
Tak, starsze wersje obsługują kilka tysięcy tokenów w jednej sesji, a nowsze nawet kilkadziesiąt tysięcy. Limit decyduje o tym, jak długi tekst możesz przeanalizować jednorazowo.
Jak tokeny wpływają na szybkość działania modeli?
Im więcej tokenów, tym dłużej trwa analiza, ponieważ każdy fragment jest przetwarzany w kontekście poprzednich. Przy długich zapytaniach czas odpowiedzi rośnie zauważalnie.
Czy w przyszłości tokeny zostaną zastąpione innym systemem rozliczeń?
Firmy eksperymentują z abonamentami, rozliczeniami za zadania i dynamicznymi taryfami. Tokeny prawdopodobnie pozostaną w tle jako techniczna jednostka, nawet jeśli użytkownik końcowy ich nie zauważy.
Dlaczego zarządzanie tokenami ma znaczenie ekologiczne?
Każdy dodatkowy token to więcej obliczeń i wyższe zużycie energii. Świadome ograniczanie liczby tokenów zmniejsza ślad węglowy i wspiera bardziej odpowiedzialne korzystanie z AI.