Jak działają modele multimodalne?
Przez lata duże modele językowe kojarzyły się wyłącznie z tekstem. Pisały artykuły, streszczały dokumenty, tworzyły kod. Dziś możliwości AI są znacznie szersze, ponieważ modele multimodalne potrafią pracować równocześnie na tekście, obrazie, dźwięku i wideo. Dzięki temu potrafią opisać zdjęcie, odczytać wykres, rozpoznać mowę i odpowiedzieć w naturalnym języku. Takie możliwości były poza zasięgiem klasycznych modeli językowych, takich jak GPT-3.5, BERT czy LLaMA 2, które działały wyłącznie na tekście i nie potrafiły łączyć wielu modalności. ChatGPT-5, Gemini i Claude 3 pokazują, że multimodalność stała się przełomem, który wyznacza tempo dalszych innowacji w AI.
Definicja multimodalnych modeli AI
Duże modele multimodalne (LMM) to systemy sztucznej inteligencji, które potrafią jednocześnie pracować na różnych typach danych, takich jak tekst, obrazy, dźwięk i wideo. Starsze rozwiązania skupiały się wyłącznie na jednej modalności, co ograniczało ich możliwości. Multimodalność wprowadza nową jakość, bo pozwala łączyć różne źródła informacji i traktować je jako jeden spójny kontekst.
Ich działanie opiera się na koncepcji wspólnej przestrzeni reprezentacji. Dane, niezależnie od tego, czy są zapisanym słowem, fotografią czy nagraniem dźwiękowym, są zamieniane na liczby w tej samej przestrzeni matematycznej. Dzięki temu system rozpoznaje, że odnoszą się do tego samego zjawiska, mimo że występują w odmiennych formach.
Multimodalne modele powstały jako odpowiedź na rosnącą złożoność danych cyfrowych. Same teksty przestały wystarczać, aby dobrze oddać kontekst, dlatego zaczęto uczyć modele integracji wielu modalności. Dziś definiuje się je jako rozwiązania, które nie tylko łączą różne źródła danych, lecz także tworzą z nich pełniejszy obraz analizowanej sytuacji. To podejście stało się fundamentem dalszego rozwoju sztucznej inteligencji.
Różnice między modelami językowymi a multimodalnymi
Definicja pokazała, czym są modele multimodalne i jak działają. Dla pełnego obrazu warto zestawić je z klasycznymi modelami językowymi, które przez lata ograniczały się wyłącznie do tekstu.
| Obszar | Modele językowe (LLM) | Modele multimodalne (LMM) |
| Dane wejściowe | tylko tekst | tekst, obrazy, dźwięk, wideo |
| Rodzaj odpowiedzi | treści pisane (np. artykuły, kod, streszczenia) | treści łączące modalności, np. opis obrazu czy analiza nagrania |
| Rodzaj odpowiedzi | praca z dokumentami, generowanie treści tekstowych | interpretacja zdjęć, analiza wykresów i filmów, interakcje głosowe |
| Efekt dla użytkownika | szybka automatyzacja zadań tekstowych | pełniejszy obraz sytuacji dzięki integracji wielu źródeł danych |
Dla firm oznacza to możliwość automatyzacji zadań, które do tej pory wymagały kilku osobnych narzędzi. Teraz mogą być obsłużone przez jeden system.
Jak multimodalne modele łączą dane tekstowe, obrazowe i dźwiękowe?
Multimodalne modele różnią się od językowych nie tylko zakresem danych, ale także architekturą. Zbudowane są z kilku warstw, które kolejno odpowiadają za przetwarzanie danych wejściowych, ich integrację i generowanie odpowiedzi.
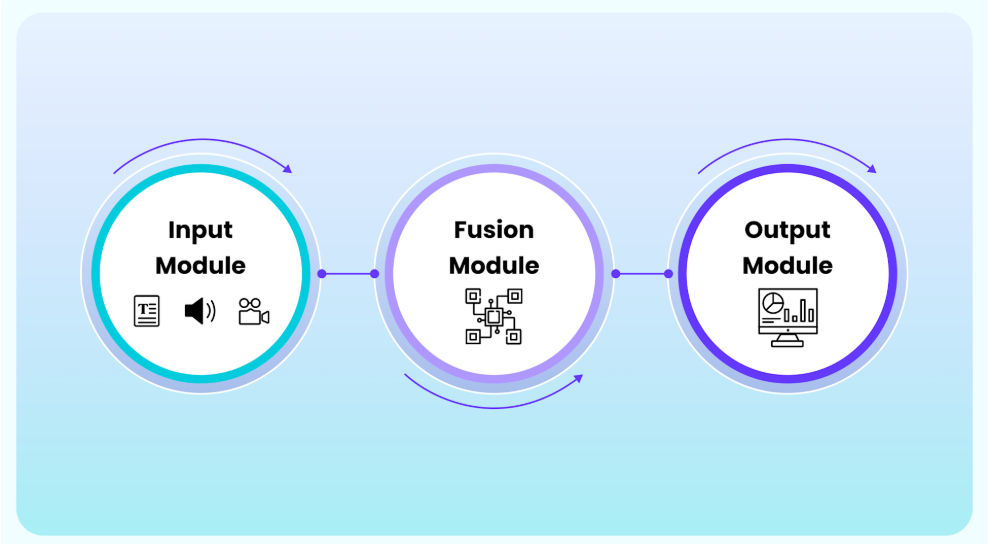
Moduły wejściowe
Każda modalność ma własny model uczący się jej specyfiki. Tekst przetwarzany jest przez sieci NLP, obrazy najczęściej przez konwolucyjne sieci neuronowe (CNN), a dźwięki i wideo przez modele sekwencyjne lub transformatory.
Warstwa fuzji
Na tym etapie dane z poszczególnych modalności są integrowane w jedną reprezentację. Mechanizmy uwagi pozwalają modelowi koncentrować się na istotnych elementach, na przykład na fragmencie wykresu, który odpowiada treści pytania użytkownika.
Moduły wyjściowe
Zintegrowane dane są następnie przekształcane w odpowiedź zrozumiałą dla użytkownika. Może to być tekst opisujący obraz, streszczenie nagrania albo rekomendacja na podstawie całego zestawu informacji.
Embeddingi multimodalne
Embeddingi multimodalne to sposób reprezentacji danych, w którym tekst, obrazy, dźwięki czy wideo zamieniane są na wektory w tej samej przestrzeni matematycznej. Dzięki temu model rozpoznaje ich semantyczne podobieństwo – np. słowo „samolot”, zdjęcie lecącej maszyny i nagranie silnika odrzutowego znajdują się blisko siebie w tej przestrzeni. To podejście umożliwia wyszukiwanie między modalnościami (opis → obraz), precyzyjniejsze rekomendacje (łączenie recenzji tekstowych i wizualnych) oraz dokładniejsze analizy treści, np. w ocenie nastrojów czy opinii.
Przykłady użycia multimodalności
Najłatwiej zrozumieć, czym jest multimodalność, gdy spojrzymy na konkretne sytuacje, w których modele są już dziś wykorzystywane.
- Opisywanie obrazów – Gemini czy Salesforce potrafią nie tylko rozpoznać, co znajduje się na zdjęciu, ale też stworzyć jego zrozumiały opis. Dzięki temu AI może wskazać elementy wykresu albo pomóc w tworzeniu treści wizualnych bez udziału człowieka.
- E-commerce – sklepy online zyskują dwie istotne korzyści: po pierwsze, modele generują opisy produktów wprost ze zdjęć, po drugie, analizują opinie klientów, fotografie i nagrania z unboxingów, aby zaproponować trafniejsze rekomendacje.
- Odpowiadanie na pytania o grafikę – zamiast żmudnie tłumaczyć, co widzimy na ekranie, wystarczy przesłać wykres lub zrzut ekranu. Model analizuje dane wizualne i tekstowe razem, a potem podaje odpowiedź, np. jakie trendy pokazuje wykres.
- Analiza nagrań wideo – GPT-4 Vision i Gemini radzą sobie z materiałami filmowymi, łącząc obraz z dźwiękiem. W praktyce oznacza to automatyczne napisy do filmów albo transkrypcje wykorzystywane w edukacji, dostępne od razu w kilku językach.
- Codzienne interakcje – multimodalność przydaje się też w prostych sytuacjach. W ChatGPT Plus można np. przesłać zdjęcie i od razu dostać odpowiedź na pytanie o to, co znajduje się na fotografii. Funkcja ta działa od października 2023.
- Obsługa klienta – chatbot w sklepie internetowym nie musi już bazować wyłącznie na tekście. Klient może przesłać zdjęcie uszkodzonego produktu, a AI rozpozna problem i zaproponuje rozwiązanie.
Zastosowania w życiu codziennym
Multimodalne modele coraz częściej pojawiają się tam, gdzie wcześniej korzystaliśmy z kilku osobnych narzędzi. Rozmowa z asystentem głosowym nie ogranicza się już do prostych pytań i odpowiedzi – system potrafi odnieść się do kontekstu i podać bardziej użyteczną informację, gdy prosimy go o pomoc. Podobna technologia wspiera osoby niewidome, które mogą skierować telefon na otoczenie i usłyszeć jego opis albo poprosić o odczytanie treści dokumentu. W biurach zyskują na znaczeniu aplikacje analizujące dokumenty – w jednym kroku potrafią przejrzeć treść, wykresy i dane liczbowe, a następnie przedstawić to w przejrzystym podsumowaniu. Coraz wyraźniej widać też wpływ na edukację: uczniowie i studenci korzystają z automatycznych transkrypcji zajęć, które są od razu dostępne w kilku językach, co ułatwia naukę i otwiera materiały na szersze grono odbiorców.
Najpopularniejsze modele multimodalne
Najwięcej uwagi przyciąga dziś GPT-5 od OpenAI. To następca GPT-4o, pierwszego modelu obsługującego tekst, obraz i audio w czasie rzeczywistym. GPT-5 oferuje bardziej stabilne działanie, lepsze rozumienie kontekstu i naturalniejsze interakcje głosowe. Obsługuje kontekst do 400 000 tokenów, co pozwala analizować bardzo obszerne dokumenty. W benchmarku SWE-bench Verified uzyskał wynik 74,9%, przewyższając GPT-4o (69,1%) i jednocześnie generując o 22% mniej tokenów oraz wykonując o 45% mniej wywołań narzędzi. W praktyce różnice między GPT-4o a GPT-5 widać przede wszystkim w jakości odpowiedzi oraz w szybkości reakcji na złożone zapytania.
Drugim najważniejszym graczem jest Gemini 2.5, rozwijany przez Google. Występuje w dwóch wariantach: Pro, przeznaczonym do zadań wymagających większej precyzji i analizy, oraz Flash, zoptymalizowanym pod kątem szybkości i efektywności. Oba modele obsługują tekst, obrazy i głos, a dzięki długiemu kontekstowi dobrze sprawdzają się zarówno w pracy badawczej, jak i w codziennych interakcjach użytkowników. Gemini 2.5 Pro pozwala na obsługę promptów o długości 1 miliona tokenów (z planami rozszerzenia do 2 mln) i osiągnął najwyższą pozycję w rankingu LMArena, wyprzedzając konkurencję o +39 punktów Elo w zadaniach wymagających rozumowania i kodowania.
Na rynku mocną pozycję ma również Claude 3 od Anthropic, dostępny w trzech wersjach – Opus, Sonnet i Haiku. Model obsługuje tekst i obrazy, a jego wyróżnikiem jest nacisk na bezpieczeństwo i przewidywalność odpowiedzi, co sprawia, że chętnie wybierają go firmy szukające stabilnych narzędzi. Najsilniejsza wersja, Claude 3 Opus, obsługuje kontekst do 200 000 tokenów. W benchmarkach osiąga m.in. ~88% w MMLU oraz ~94% w GSM8K, co plasuje go wyżej niż GPT-4 Turbo w zadaniach matematycznych. W multimodalnym teście MMMU uzyskał wynik 59,4%, co potwierdza jego możliwości w łączeniu danych wizualnych i tekstowych.
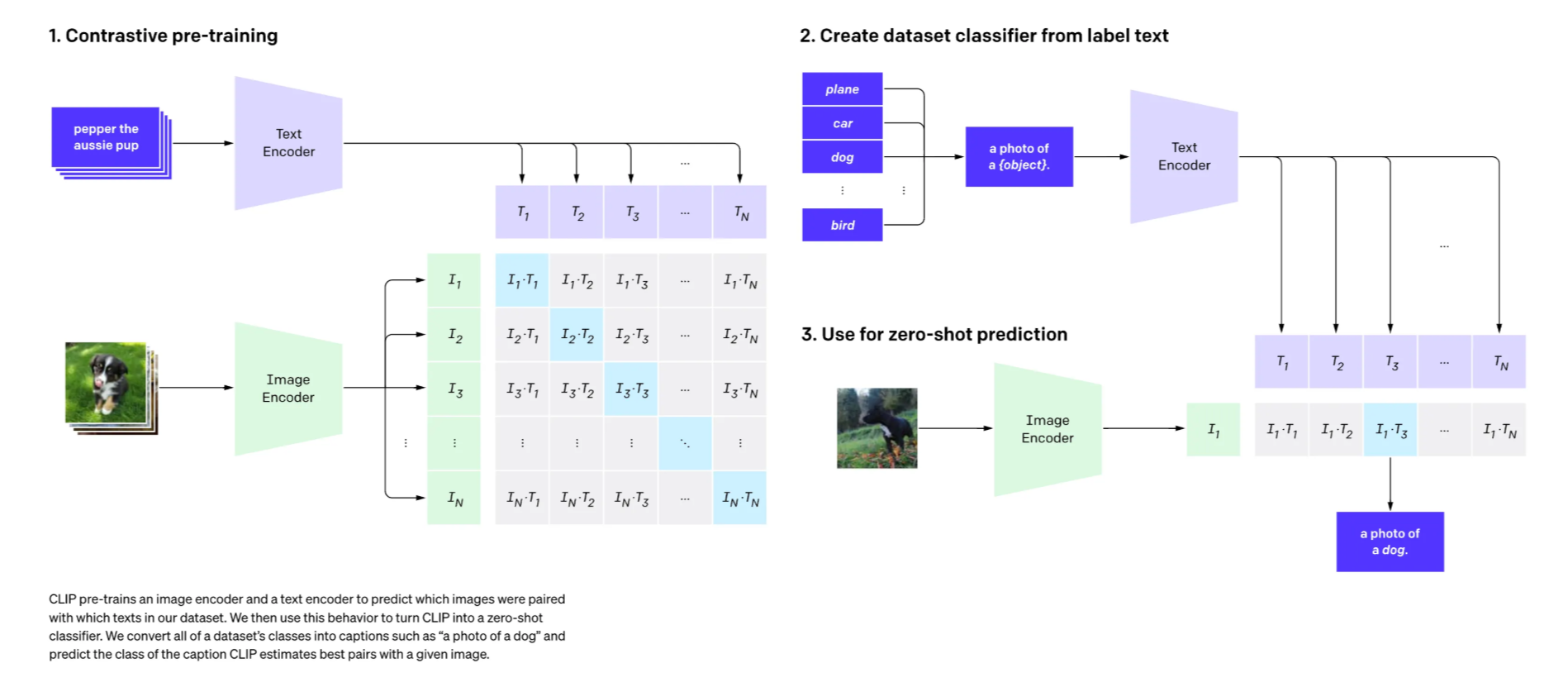
W historii rozwoju multimodalnych systemów warto wspomnieć o CLIP, modelu stworzonym przez OpenAI w 2021 roku. Nie jest to narzędzie używane bezpośrednio przez użytkowników tak jak GPT-5 czy Gemini, lecz fundament, na którym powstało wiele późniejszych rozwiązań. CLIP został wytrenowany na zbiorze 400 milionów par obraz-tekst i nauczył się mapować obrazy i opisy w jednej przestrzeni semantycznej, dzięki czemu możliwe stało się dopasowanie opisu do obrazu lub odwrotnie. Technologia ta została wykorzystana m.in. w modelach DALL·E, gdzie odpowiadała za ocenę, czy wygenerowana grafika pasuje do podanego promptu tekstowego. Choć CLIP nie jest samodzielnym produktem, jego koncepcje i mechanizmy stały się fundamentem dla nowoczesnych modeli multimodalnych.
Pułapki i ograniczenia multimodalnej sztucznej inteligencji
Modele multimodalne potrafią generować wyniki, które wyglądają przekonująco, ale nie zawsze są poprawne. Przykładem są błędne opisy obrazów – system potrafi pominąć istotny element zdjęcia albo zasugerować szczegół, którego faktycznie nie ma. Podobne problemy występują przy analizie dokumentów, gdzie modele mogą źle odczytać wartości liczbowe z tabeli lub błędnie zinterpretować dane z wykresu.
Na ograniczenia zwracają uwagę także twórcy modeli. Claude 3 Opus, mimo świetnych wyników w benchmarkach (MMLU 86,8%, GSM8K 95%, MMMU 59,4%), wciąż może podać błędne odpowiedzi, jeśli dane wejściowe są niepełne lub niejednoznaczne. W przypadku GPT-5 wyniki na SWE-bench Verified (74,9%) pokazują znaczną poprawę względem GPT-4o (69,1%), ale też dowodzą, że blisko 25% zadań kodowych nadal kończy się niepowodzeniem.
Ważnym wyzwaniem są także koszty. Trening CLIP wymagał aż 400 milionów par obraz–tekst, co pokazuje, jak ogromnych zbiorów i mocy obliczeniowej potrzebują takie systemy. W zastosowaniach komercyjnych koszty również są istotne: Gemini 2.5 Pro kosztuje ok. 1,25 USD za milion tokenów wejściowych i 10 USD za milion tokenów wyjściowych, co przy długich kontekstach rzędu milionów tokenów oznacza spore wydatki.
W którą stronę rozwija się multimodalność?
Rozwój multimodalnych systemów koncentruje się dziś głównie na trzech obszarach. Pierwszy to wydłużanie kontekstu – GPT-5 radzi sobie z zapytaniami rzędu 400 tys. tokenów, a Gemini 2.5 Pro już dziś obsługuje 1 mln tokenów i testowane są wersje o 2 mln. To otwiera drogę do analizy setek stron dokumentów czy wielogodzinnych nagrań w jednej sesji.
Drugim kierunkiem jest dokładność w zadaniach multimodalnych. Claude 3 Opus osiąga 59,4% w benchmarku MMMU, który sprawdza zdolność do integracji tekstu i obrazu. Wynik ten jest wyższy niż w przypadku GPT-4, co pokazuje, że modele coraz lepiej radzą sobie z pytaniami wymagającymi łączenia danych wizualnych i tekstowych.
Trzeci obszar to nowe modalności i transparentność. Już dziś testowane są rozwiązania pozwalające na analizę gestów i mimiki, co w przyszłości może znaleźć zastosowanie w obsłudze klienta czy medycynie. Jednocześnie dostawcy pracują nad metodami, które pozwolą wyjaśnić, dlaczego model podał konkretną odpowiedź, aby zwiększyć zaufanie użytkowników.