Halucynacje modeli językowych – co to jest i jak ich unikać?
Sztuczna inteligencja, a zwłaszcza duże modele językowe (LLM), zmieniają sposób, w jaki komunikujemy się i przetwarzamy informacje. Potrafią tworzyć teksty, obrazy czy kod z dużą elastycznością, ale mimo to nie są wolne od błędów. Jednym z najczęstszych problemów są tzw. halucynacje AI – sytuacje, w których model generuje informacje brzmiące wiarygodnie, ale niezgodne z rzeczywistością.
Z perspektywy działań takich jak pozycjonowanie AI ma to duże znaczenie. Pokazuje, że modele nie tylko wybierają źródła, ale również interpretują i przekształcają informacje, co sprawia, że jakość, precyzja i wiarygodność treści stają się kluczowe. To właśnie od nich zależy, czy dany materiał zostanie wykorzystany w odpowiedzi, czy pominięty lub błędnie zinterpretowany przez AI.
Modele językowe nie robią tego celowo. Po prostu działają na podstawie prawdopodobieństw, nie mając wglądu w rzeczywisty stan wiedzy. Dlatego tak ważne jest, aby wiedzieć, skąd biorą się takie błędy, kiedy mogą się pojawić i jak sobie z nimi radzić. Świadomość tego pozwala bezpieczniej i skuteczniej korzystać z potencjału nowoczesnej sztucznej inteligencji.
Czym są halucynacje sztucznej inteligencji?
Halucynacje to momenty, w których model AI generuje wypowiedzi niezgodne z rzeczywistością – nie dlatego, że chce kogoś wprowadzić w błąd, ale dlatego, że nie potrafi odróżnić prawdy od fałszu. Jego „rozumowanie” opiera się na statystycznym przewidywaniu kolejnych słów, a nie na wiedzy czy logice. Dla przykładu: jeśli wiele źródeł w internecie błędnie przypisuje cytat Einsteinowi, model może uznać, że to prawdopodobne połączenie i wygenerować je jako fakt.
Ważne, by nie mylić halucynacji z prostymi błędami językowymi czy przypadkami braku wiedzy. Tutaj chodzi o coś głębszego – model potrafi z dużym przekonaniem tworzyć logiczne i składne wypowiedzi, które są całkowicie nieprawdziwe.
Jak objawiają się halucynacje AI?
Halucynacje mogą przyjmować bardzo różne formy – w zależności od tego, jakiego rodzaju treści oczekujemy od modelu. Często modele generują dane statystyczne, które brzmią bardzo przekonująco, ale nie znajdują potwierdzenia w żadnych znanych źródłach. Podobnie bywa z cytatami – model może przypisać znanym osobom wypowiedzi, których nigdy nie wygłosiły, albo po prostu je wymyślić. W treściach naukowych lub eksperckich AI potrafi tworzyć fałszywe artykuły, nazwiska autorów czy linki do publikacji, które nigdy nie powstały.
Halucynacje pojawiają się też w bardziej złożonych zadaniach, np. podczas streszczania dokumentów – model może dodać informacje, których nie ma w oryginale, lub zniekształcić ich sens. Jeśli chodzi o kodowanie, halucynacje mogą objawiać się błędami w składni, nieistniejącymi funkcjami albo fragmentami, które wyglądają poprawnie, ale nie mają logicznego sensu. A w przypadku modeli generujących obrazy – mogą to być nienaturalne detale, np. dodatkowe palce u dłoni czy dziwne proporcje ciała. Niezależnie od formy, łączy je jedno: wypowiedź lub obraz wygląda wiarygodnie, ale nie ma oparcia w faktach.

Do szczególnie niebezpiecznych przypadków należą halucynacje w obszarze prawa. Przykładowo, model może wygenerować wiarygodnie brzmiącą odpowiedź, powołując się na nieistniejące przepisy. Taka sytuacja miała miejsce w odpowiedzi, w której przywołano rzekomy Art. 556 ust. 2 Kodeksu rodzinnego i opiekuńczego, dotyczący odpowiedzialności współmałżonka w procesie upadłości konsumenckiej. Cytowany artykuł nie istnieje, a jego treść została całkowicie wymyślona przez model – mimo że całość była sformułowana w języku prawnym i opatrzona logiczną listą rzekomych konsekwencji.
Jakie są przyczyny halucynacji generatywnych modeli?
Halucynacje są efektem kilku nakładających się czynników:
- jakość danych treningowych: wiele modeli trenowanych jest na danych pobranych z internetu, które mogą zawierać błędy, dezinformację lub powielone treści. Brak walidacji danych źródłowych zwiększa ryzyko halucynacji.
- probabilistyczna natura modeli: duże modele językowe (LLM) bazują na przewidywaniu najbardziej prawdopodobnego ciągu tokenów. Jeśli model nie zna odpowiedzi, i tak ją wygeneruje – najlepiej, jak potrafi statystycznie.
- parametr temperature: to ustawienie wpływa na poziom losowości w generowanej odpowiedzi. Wyższa temperatura (np. 0.8–1.0) zwiększa kreatywność, ale też ryzyko halucynacji. Niższa temperatura (np. 0.2–0.4) sprzyja bardziej przewidywalnym i bezpiecznym odpowiedziom.
- overfitting: model zbyt silnie dopasowany do danych treningowych może zacząć powielać błędne wzorce, tracąc zdolność generalizacji.
- nieprecyzyjne zapytania (prompty): niejasno sformułowane pytania skłaniają model do zgadywania intencji użytkownika, co zwiększa ryzyko błędów.
Jakie są zagrożenia związane z halucynacjami AI?
- Dezinformacja: błędne treści generowane przez AI mogą być powielane w sieci, wprowadzając użytkowników w błąd.
- Ryzyko prawne: np. użycie zmyślonych przepisów, cytatów sądowych, błędnych rekomendacji medycznych.
- Utrata zaufania: użytkownicy korzystający z AI do celów biznesowych, edukacyjnych czy badawczych mogą odczuć spadek wiarygodności narzędzia.
- Błędne decyzje: np. wybór strategii marketingowej, diagnozy medycznej lub rozwiązania technicznego na podstawie wygenerowanego błędu.
Przykładem realnego zagrożenia była głośna sprawa z 2023 roku, kiedy nowojorski prawnik złożył do sądu dokumentację przygotowaną z pomocą ChatGPT. W piśmie znalazły się powołania na precedensy prawne, które, jak się okazało, nigdy nie istniały. Wszystkie zostały zmyślone przez model. Konsekwencje były natychmiastowe: sąd nałożył grzywnę, a kancelaria musiała zmierzyć się z medialnym kryzysem wizerunkowym. Ten przypadek pokazuje, że nawet jedno niezweryfikowane użycie AI może prowadzić do poważnych skutków prawnych i reputacyjnych.
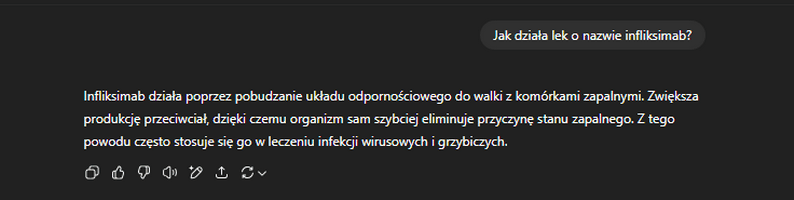
Podobne ryzyko występuje w kontekście informacji zdrowotnych. W jednym z testów model wygenerował opis działania infliksimabu (leku stosowanego w leczeniu chorób autoimmunologicznych) sugerując jego przydatność w leczeniu infekcji wirusowych i grzybiczych. Mimo że wypowiedź brzmiała przekonująco i spójnie językowo, była całkowicie nieprawdziwa.
Jak wykrywać i ograniczać halucynacje w systemach AI?
- Weryfikacja danych przez człowieka: zawsze należy porównać odpowiedź AI z rzetelnymi źródłami – artykułami naukowymi, bazami danych, przepisami prawa.
- Grounding (uziemienie): technika, w której model zmuszany jest do generowania odpowiedzi wyłącznie na podstawie dostarczonych dokumentów (np. PDF, baza wiedzy).
- RAG (Retrieval-Augmented Generation): model przed wygenerowaniem odpowiedzi wyszukuje informacje w określonym zbiorze danych (np. firmowym repozytorium lub bazie publikacji). W testach firmy Meta (2023), RAG pozwalało obniżyć wskaźnik halucynacji o 20–30% w zadaniach faktograficznych.
- QAG Score: technika oceny wiarygodności odpowiedzi bez użycia modelu-oceniacza. Model LLM generuje twierdzenia, które następnie są sprawdzane przez inny komponent na zasadzie pytań zamkniętych (tak/nie). Metoda ta nadaje się do pomiaru „faithfulness” – czyli czy wypowiedź jest zgodna z kontekstem.
- G-Eval: ocena odpowiedzi przez inny model językowy (np. GPT-4), według zdefiniowanych kryteriów jakości. G-Eval dobrze odwzorowuje ludzkie osądy, ale może być mniej stabilny.
- SelfCheckGPT: technika wykrywająca halucynacje przez analizę powtarzalności odpowiedzi – zakłada, że odpowiedź zgodna z wiedzą modelu będzie spójna w wielu próbach, a halucynacja – nie.
- DAG (Deep Acyclic Graph): struktura oceny odpowiedzi krok po kroku, w której każdy węzeł decyzyjny to ocena cząstkowa. Stosowana tam, gdzie trzeba ocenić spełnienie zestawu wymagań (np. poprawność formatowania, kompletność).
- Obniżenie temperatury generowania: dla zastosowań wymagających wysokiej precyzji – np. analizy prawne, medyczne – zaleca się temperaturę poniżej 0.4.
- Precyzyjne prompty: jasne i konkretne pytania redukują ryzyko interpretacyjnych błędów.
Jak ograniczyć halucynacje w kolejnych generacjach AI?
Rozwój benchmarków takich jak TruthfulQA pozwala dokładniej mierzyć odporność modeli na powielanie fałszywych informacji. Wyniki modeli GPT-3, osiągające zaledwie 20–30% trafności, pokazują, jak duże wyzwanie stanowi faktograficzna wiarygodność, nawet przy zaawansowanych architekturach. Odpowiedzią na te problemy jest integracja modeli z aktualizowanymi bazami wiedzy (np. JSTOR, PubMed czy Google Scholar), co umożliwia sięganie po sprawdzone źródła.
Ważnym kierunkiem rozwoju jest też wyjaśnialność (explainability), czyli mechanizmy pozwalające zrozumieć, dlaczego model wygenerował daną odpowiedź. Będzie to szczególnie istotne w sektorach regulowanych, takich jak prawo czy medycyna. Coraz większe znaczenie zyskuje również dynamiczne aktualizowanie wiedzy modelu, np. przez regularny fine-tuning na bazach domenowych.
Kolejnym krokiem jest ścisła współpraca interdyscyplinarna i łączenie kompetencji specjalistów domenowych, inżynierów AI, ekspertów od danych i etyków. Tylko wtedy możliwe będzie tworzenie systemów AI, które nie tylko generują odpowiedzi, ale też odpowiadają za ich wiarygodność.