
Duplicate content – czym jest i jak się go pozbyć?
Pojęcie duplicate content (duplikaty treści) często pojawia się jako jedna z kluczowych przeszkód w efektywnym pozycjonowaniu stron internetowych. Ale czym dokładnie jest ten tajemniczy „duplicate content” i jakie realne skutki może przynieść Twojej stronie internetowej? Czy zawsze jest to problem, czy może istnieją okoliczności, w których duplikacja treści niekoniecznie pogorszy wyniki Twojej strony?
Co to jest duplicate content?
Duplicate content (zduplikowana treść) to sytuacja, w której identyczna lub bardzo podobna treść występuje na więcej niż jednej stronie internetowej. Może to mieć miejsce w obrębie jednej witryny (duplikacja wewnętrzna) lub pomiędzy różnymi witrynami (duplikacja zewnętrzna). Wyszukiwarki, takie jak Google, traktują takie przypadki jako potencjalny problem, ponieważ ich celem jest dostarczanie użytkownikom unikalnych i wartościowych treści. Duplicate content może powstać celowo, np. poprzez kopiowanie treści, lub nieumyślnie, w wyniku błędów technicznych lub niedostatecznej optymalizacji.
Czym są wewnętrzne duplikaty treści?
Wewnętrzne duplikaty treści to sytuacja, w której ta sama lub bardzo podobna treść jest dostępna na różnych podstronach tej samej witryny. Problem ten może wynikać z błędów technicznych, niewłaściwego projektowania struktury strony lub automatyzacji publikowania treści. Najczęściej występuje w dużych serwisach, takich jak sklepy internetowe, blogi czy portale informacyjne, gdzie powielanie treści może być niezamierzone, ale negatywnie wpływa na SEO.
Przykłady wewnętrznej duplikacji treści:
- Paginacja (numerowanie stron): Strony kategorii w e-commerce z powtarzającymi się opisami na każdej stronie paginacji
- Opis w stopce: Długi, zoptymalizowany pod kątem SEO opis powtarzający się na każdej podstronie witryny
- Dynamiczne adresy URL: Te same treści dostępne pod różnymi adresami
- Powielone opisy produktów: Identyczne treści w różnych wariantach produktu
- Powtarzalne treści na stronach filtrowania: Podstrony z różnymi kombinacjami filtrów, które pokazują te same produkty
- Strony archiwalne bloga: Archiwalne widoki bloga zawierające identyczne fragmenty wpisów
- Strony wyszukiwania wewnętrznego: Wyniki wyszukiwania na stronie, które duplikują treści istniejące w kategoriach lub produktach
Konsekwencje wewnętrznych duplikatów treści
Gdy roboty indeksujące napotykają zduplikowaną treść, mają trudności z określeniem, która wersja strony jest najważniejsza. Może to prowadzić do sytuacji, w której żadna z wersji nie jest odpowiednio promowana w wynikach wyszukiwania. Dodatkowo problematyczna jest utrata budżetu indeksowania (tzw. crawl budget) – zamiast skupić się na nowych, wartościowych treściach, roboty tracą czas na analizę zduplikowanych stron.
Jak sobie radzić z wewnętrznym duplicate content?
Aby skutecznie zapobiegać wewnętrznym duplikatom treści, warto stosować różnorodne rozwiązania dostosowane do specyfiki problemu. Przykładowe działania to:
- Usuwanie powtarzających się opisów na dalszych stronach paginacji – np. pozostawienie unikalnego opisu tylko na pierwszej stronie kategorii.
- Dodawanie tagu kanonicznego (rel=”canonical”) – wskazanie wyszukiwarkom, która wersja postrony jest tą główną.
- Stosowanie metatagu
noindexw przypadkach, gdy strony (np. wyniki wyszukiwania wewnętrznego) nie powinny być indeksowane. - Różnicowanie treści za pomocą nagłówków H1 i H2 – dostosowanie ich do specyfiki konkretnej podstrony.
- Optymalizacja meta tagów (title, description) – uniknięcie powielania tych elementów na różnych stronach.
- Blokowanie niepotrzebnych stron w pliku robots.txt – np. wykluczanie filtrów generujących duplikaty treści.
- Unikalne opisy produktów i kategorii – nawet przy niewielkich różnicach między wariantami produktów.
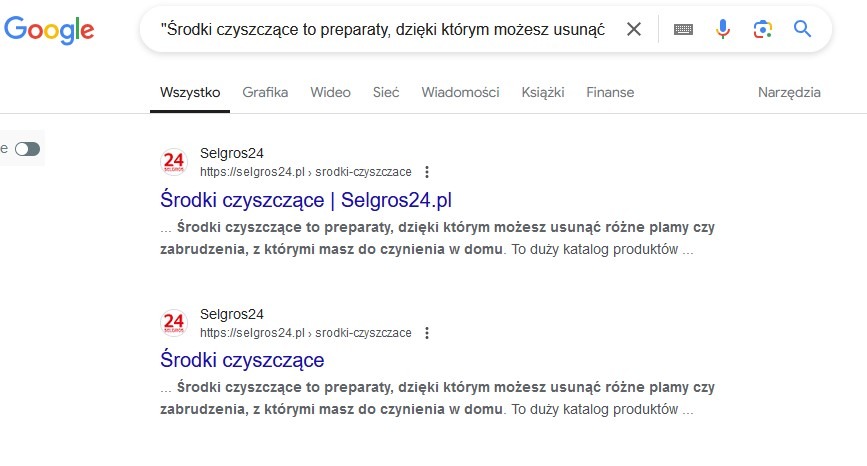
Przykład duplikacji wewnętrznej, gdzie opis kategorii został zaindeksowany z dwóch różnych stron paginacji
Duplikaty zewnętrzne – czyli jakie?
Zewnętrzne duplikaty treści pojawiają się, gdy identyczna lub bardzo podobna treść jest dostępna na różnych witrynach internetowych. Mogą wynikać z celowego kopiowania treści lub z niezamierzonych działań, takich jak korzystanie z tych samych opisów produktów dostarczonych przez producenta. Problem ten jest szczególnie istotny, ponieważ wyszukiwarki mają trudność w ustaleniu, która strona powinna być uznana za oryginalne źródło, co może prowadzić do spadków widoczności obu witryn.
Przykłady zewnętrznej duplikacji treści:
- Kopiowanie opisów produktów: Sklepy korzystające z tych samych, dostarczonych przez producenta opisów, np. dwa różne sklepy mają identyczny tekst dla tego samego modelu telefonu.
- Publikacja wielokanałowa: Publikowanie tego samego artykułu na kilku portalach np. na stronie internetowej, mediach społecznościowych itp. bez wprowadzenia unikalnych zmian lub przypisania źródła.
- Scraping treści: Witryny kopiujące treści z innych stron w celu zwiększenia swojego ruchu (często są to strony niskiej jakości, tzw. scraper sites).
- Publikacje prasowe i materiały PR: Firmy wysyłające identyczne komunikaty prasowe do wielu mediów, które publikują je w niezmienionej formie.
- Treści partnerskie: Strony należące do sieci afiliacyjnych często powielające opisy produktów dostarczone przez reklamodawców.
Jak Google postrzega zewnętrzny duplicate content?
Zewnętrzne duplikaty treści mogą mieć poważne konsekwencje dla reputacji witryny i jej pozycji w wyszukiwarkach, szczególnie gdy inne strony zaczynają być uznawane za oryginalne źródło. Wyszukiwarki, takie jak Google, dążą do prezentowania użytkownikom najbardziej wartościowych i oryginalnych treści. Jeśli jednak nasza witryna i strona kopiująca zawierają identyczny materiał, algorytmy mogą mieć trudności z rozpoznaniem, kto jest jego autorem. W efekcie może dojść do sytuacji, w której kopia jest wyżej oceniana niż oryginał, co obniża widoczność naszej strony. Takie problemy wpływają również na reputację witryny. Gdy użytkownicy trafią na kopię treści na innych stronach, mogą zacząć postrzegać naszą stronę jako mniej autentyczną lub wtórną.
Jak unikać zewnętrznych duplikatów treści?
Najważniejszym krokiem w eliminacji zewnętrznych duplikatów treści jest tworzenie unikalnych materiałów. Warto opracowywać własne opisy produktów, artykuły czy teksty promocyjne, zamiast korzystać z gotowych szablonów lub materiałów dostarczonych przez innych. Jeśli jednak dojdzie do sytuacji, w której ktoś skopiuje nasze treści bez zgody, pierwszym krokiem powinien być kontakt z administratorem witryny, która powieliła treść, z prośbą o jej usunięcie lub przypisanie autorstwa. W przypadku braku reakcji, można zgłosić naruszenie praw autorskich za pomocą formularza DMCA w Google, co pozwoli na usunięcie powielonych treści z wyników wyszukiwania. Takie działania pomagają chronić autentyczność naszej witryny i jej widoczność w wyszukiwarkach.
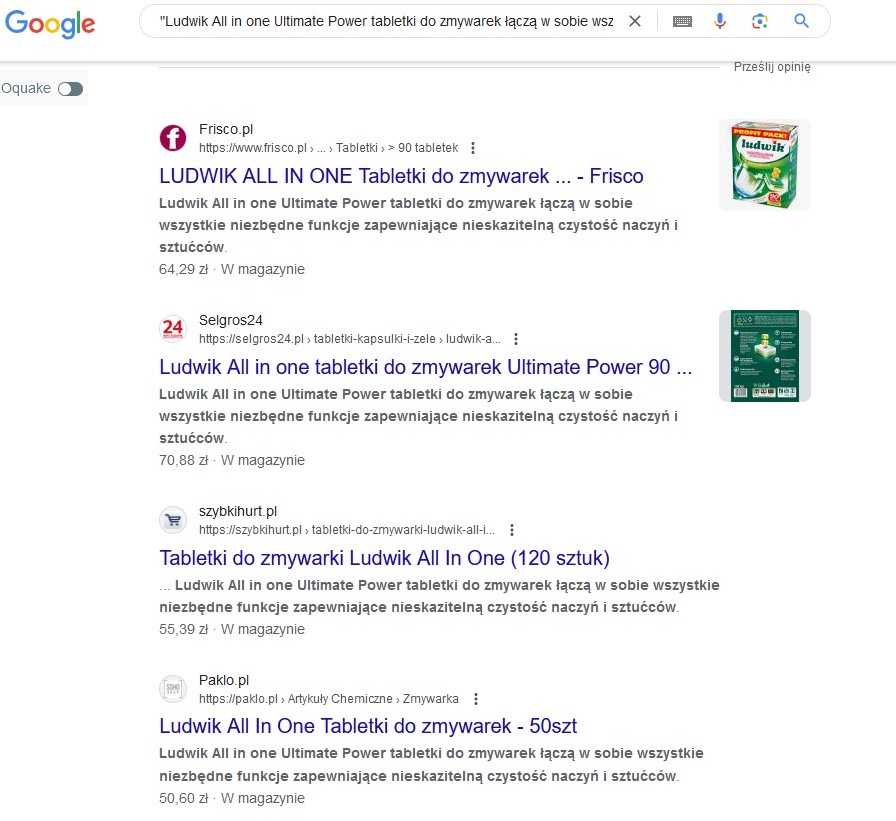
Przykład zewnętrznego duplikatu treści, gdzie wykorzystano ten sam opis producenta.
Jak sprawdzić, czy na Twojej stronie występują duplikaty treści?
Aby sprawdzić, czy Twoja witryna zawiera zduplikowane treści (zarówno wewnętrzne, jak i zewnętrzne), możesz skorzystać z różnych narzędzi. Jednym z najpopularniejszych jest Screaming Frog SEO Spider, które przeskanuje Twoją stronę i pomoże zidentyfikować powtarzające się treści w obrębie witryny. Narzędzie to pozwala analizować elementy takie jak meta title, meta description, czy powtarzalne treści HTML. Dla analizy zewnętrznej, warto wykorzystać narzędzia typu Copyscape lub PlagScan, które umożliwiają porównanie Twojej treści z innymi stronami w sieci.
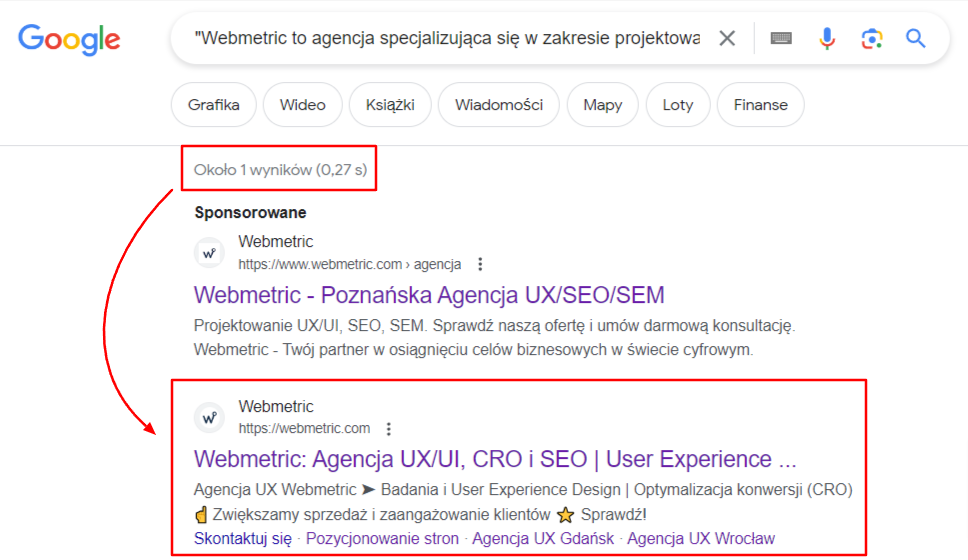
Ręczna weryfikacja duplikatów treści w Google
Ręczne sprawdzenie duplikatów
Nie możemy również zapomnieć o najprostszej metodzie, czyli weryfikacji tekstu bezpośrednio w Google. Do ręcznego sprawdzania fragmentów tekstu wystarczy wyszukać fragmenty tekstu w cudzysłowie, aby zobaczyć, czy istnieją inne strony z identycznymi treściami. Choć jest to metoda bardziej czasochłonna, może okazać się niezwykle użyteczna, szczególnie gdy chcemy sprawdzić unikalność konkretnych fragmentów tekstu. Ręczna inspekcja polegająca na czytaniu i analizowaniu publikowanych tekstów jest kolejną opcją – choć jest to proces bardzo czasochłonny, pozwala na dokładne przeanalizowanie treści i porównanie jej z innymi źródłami online. W tym kontekście, ważne jest, aby być na bieżąco z najnowszymi publikacjami w swojej dziedzinie, co ułatwi identyfikację ewentualnych duplikatów. Na koniec, warto podkreślić, że tworzenie oryginalnych, wartościowych treści powinno być priorytetem w każdej strategii pozycjonowania, ponieważ to one budują autorytet i wiarygodność strony.
Wpływ duplicate content na pozycjonowanie
Chcąc konkurować o wysokie pozycje w wynikach wyszukiwania Google, zawsze należy zwrócić szczególną uwagę na jakość i unikalność treści na stronie. Bez względu na branżę czy wielkość pozycjonowanej strony, unikalne teksty są ważnym czynnikiem mającym wpływ na pozycje w wynikach wyszukiwania.
Zarówno wewnętrzne jak i zewnętrzne duplikaty treści mają negatywny wpływ na to, jak algorytmy Google oceniają naszą stronę. Warto więc zadbać o unikalność tekstów, nie tylko tych, które tworzymy ale także tych, które już znajdują się na naszej stronie.













![Algorytmy Google – rodzaje i działanie [2026]](https://webmetric.com/wp-content/uploads/2025/11/algorytmy-google.jpg)
