Co to jest LLM i jak działają duże modele językowe?
Jeśli miałbyś wskazać, co odróżnia człowieka od maszyny, być może jednym z pierwszych skojarzeń byłaby mowa. Słowa, zdania, sens, żarty, styl, ton – to wszystko przez lata wydawało się wyłącznie naszą domeną. A jednak od pewnego czasu maszyny mówią. Piszą. Odpowiadają. I coraz częściej robią to w sposób zaskakująco… ludzki.
Modele językowe, nazywane często LLM (skrót od angielskiej nazwy dużych modeli językowych), to jedne z najbardziej przełomowych osiągnięć w świecie nowoczesnych technologii. Budzą fascynację, lęk i ekscytację. Czym właściwie są? Jak działają? Dlaczego wzbudzają tyle emocji i o co tyle szumu? Przeczytaj ten artykuł, aby poznać szczegóły!
Czym w ogóle jest LLM?
Duży model językowy (LLM – Large Language Model) to system komputerowy stworzony do przetwarzania, analizy i generowania tekstu w języku naturalnym. Działa w oparciu o zaawansowaną matematykę i statystykę, ale jego zadanie jest dość „ludzkie”: rozumieć język i tworzyć odpowiedzi, które mają sens.
Na pierwszy rzut oka brzmi to, jak klasyczny program komputerowy, lecz różnica jest zasadnicza – LLM nie działa na zasadzie zbioru sztywnych reguł, ale na podstawie wzorców wyuczonych z gigantycznych zbiorów tekstu. Mówiąc wprost – „czyta” miliony książek, artykułów, stron internetowych i analizuje, jak układają się słowa, zdania, emocje, struktury. A potem – przewiduje, jakie słowo może pojawić się jako kolejne.
Dlaczego są „duże”? I co znaczy „model”?
Zacznijmy od końca. „Model”, czyli uproszczony opis rzeczywistości. W tym przypadku – opis tego, jak działa język. Model językowy to więc matematyczna struktura odzwierciedlająca prawidłowości, które zachodzą w języku, oparta na danych wejściowych.
Z kolei „duży” w LLM nie odnosi się wyłącznie do objętości kodu. Mowa w tym przypadku o rozmiarze:
- danych – liczba słów, zdań, dokumentów używanych do „nauczenia” modelu idzie w setki miliardów;
- parametrów – w modelach takich jak GPT-3 liczba parametrów (czyli wag, które model sam ustala podczas uczenia) przekraczała 175 miliardów;
- możliwości – duże modele są w stanie pisać eseje, streszczać artykuły naukowe, tłumaczyć z języka na język czy odpowiadać na pytania z wiedzy ogólnej.
Dla porównania – ludzki mózg posiada około 86 miliardów neuronów. Model GPT-4, według szacunków niektórych źródeł, może mieć ich wielokrotność. Nie oznacza to, że jest mądrzejszy – ale jego skala operacyjna okazuje się wyjątkowo potężna.
Jak uczą się modele językowe?
Model nie rodzi się z wiedzą. Musi ją zdobyć. Proces ten nazywany jest uczeniem maszynowym. Polega na przetwarzaniu ogromnych ilości tekstu i analizowaniu, jakie słowa występują obok siebie, jakie konstrukcje pojawiają się w określonych kontekstach, a także jakie formy są logiczne.
Najczęściej wykorzystywaną metodą w LLM jest tzw. uczenie nadzorowane i nienadzorowane – co warto rozumieć w następujący sposób:
- model analizuje tekst, aby zrozumieć, które słowa pojawiają się razem;
- potem próbuje przewidywać brakujące fragmenty – np. jakiego słowa brakuje w zdaniu;
- jego błędy są analizowane, a parametry dostosowywane – aż do momentu, kiedy skuteczność osiąga zadowalający poziom.
„Właśnie dlatego LLM nie „rozumie” tekstu w ludzkim sensie. On nie „wie”, że Warszawa to stolica Polski. Wie tylko, że słowo „Warszawa” najczęściej pojawia się w kontekście „stolica Polski” – i na tej podstawie wyciąga wnioski”. – Marcin Siemiginowski, Content Marketing Manager
Techniczne podstawy w zakresie LLM
Modele LLM są oparte na architekturze zwanej „transformatorami”. Transformator analizuje dane wejściowe równolegle, a nie po kolei, jak wcześniejsze modele. W konsekwencji może wychwytywać zależności między słowami znajdującymi się nawet daleko od siebie w zdaniu.
Najważniejszym elementem tej architektury jest tzw. mechanizm uwagi (ang. attention), czyli sposób „skupienia się” na tych częściach tekstu, które mają największe znaczenie w danym kontekście.
Jak to działa? Jeśli wpiszesz pytanie: „Gdzie leży Zakopane?”, model potrafi wychwycić, że słowo „Zakopane” jest istotą zapytania – i na tej podstawie generuje logiczną odpowiedź.
Modele językowe w rzeczywistości – cała prawda o LLM
Chociaż wszystko brzmi jak szczyt techniki – modele LLM nie są „inteligentne” w klasycznym sensie. Nie mają świadomości. Nie rozumieją znaczeń. Nie czują. Nie mają motywacji ani celów. Ich siłą jest umiejętność tworzenia ciągów znaków, które są zgodne z tym, co model „widział” w przeszłości.
To bardzo mocna umiejętność, ale – i to ważne – ograniczona. Modele potrafią się mylić, konfabulować, a nawet tworzyć informacje, które brzmią logicznie, ale nie mają żadnego pokrycia w faktach. Nazywa się to halucynacją modelu.
Dlatego zawsze warto traktować odpowiedzi modeli wyłącznie jako narzędzie wspierające myślenie.
Skąd modele LLM biorą dane?
Modele językowe są trenowane na ogromnych zbiorach tekstu pochodzących z:
- książek – zarówno klasyki literatury, jak i tekstów naukowych;
- encyklopedii i słowników – np. dane z Wikipedii, ale też z wolnodostępnych źródeł akademickich;
- stron internetowych – forów, blogów, artykułów prasowych;
- dialogów – np. transkrypcji rozmów lub rozmów symulowanych.
Dane są zazwyczaj publiczne i legalnie dostępne – chociaż to również temat, który budzi kontrowersje i bywa przedmiotem debat etycznych.
Według badania opublikowanego przez EleutherAI, dane używane do trenowania największych modeli obejmują nawet ponad 800 GB tekstu w formacie surowym – co daje równowartość setek milionów stron książek.

Badania EleutherAI na temat zbiorów danych LLM. Źródło: www.eleuther.ai/papers-blog/the-pile-an-800gb-dataset
Dlaczego teraz jest o nich tak głośno?
Rok 2023 i 2024 to prawdziwy wybuch popularności LLM. W ciągu zaledwie kilku miesięcy miliony ludzi na całym świecie zaczęły korzystać z aplikacji opartych o duże modele językowe – do pisania tekstów, kodowania, tłumaczeń, nauki, a nawet terapii (choć to akurat kontrowersyjne).
W 2023 roku liczba użytkowników jednego z najpopularniejszych modeli osiągnęła ponad 100 milionów w ciągu zaledwie kilkunastu miesięcy od premiery – co czyni go jednym z najszybciej rosnących produktów technologicznych w historii.
Dlaczego tak się stało? Powody są proste:
- po raz pierwszy modele generujące język zostały udostępnione dla każdego;
- interfejsy stały się łatwe w obsłudze – wpisujesz tekst, dostajesz odpowiedź;
- jakość generowanych treści przekracza oczekiwania – są spójne, logiczne, często zadziwiające;
- czas reakcji modeli skrócił się do ułamków sekundy – dzięki temu korzystasz z nich niemal w czasie rzeczywistym;
- zredukowano koszty dostępu – wiele rozwiązań stało się darmowych lub dostępnych w modelu subskrypcyjnym;
- modele zaczęły obsługiwać wiele języków – również polski, co zwiększyło ich użyteczność lokalnie;
- interfejsy zostały zintegrowane z popularnymi aplikacjami – korzystasz z nich w przeglądarkach, edytorach tekstów, komunikatorach;
- technologia zyskała rozpoznawalność – pojawiała się w mediach, debatach publicznych, szkoleniach (wpłynęło to na zmniejszenie dystansu psychologicznego).
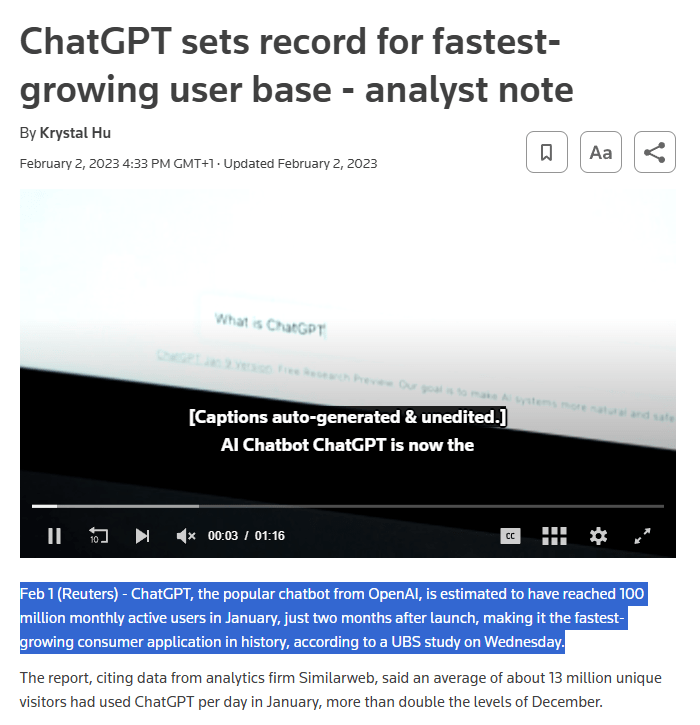
Dane Reuters na temat jednego z najpopularniejszych modeli. Źródło: www.reuters.com/technology/chatgpt-sets-record-fastest-growing-user-base-analyst-note-2023-02-01/
Jak działa trenowanie dużego modelu językowego?
Na pierwszy rzut oka może się wydawać, że stworzenie LLM to sprawa dość prosta. Wrzućmy ogromny zbiór tekstów, pozwólmy maszynie je „przeczytać”, a potem każmy jej odpowiadać na pytania. Ale prawda jest zupełnie inna. To proces długi, żmudny i kosztowny – nie tylko w sensie pieniędzy, ale też mocy obliczeniowej i ludzkiego zaangażowania.
Czym jest „parametr” w modelu?
Gdy słyszysz, że dany model ma np. 175 miliardów parametrów, może brzmieć to dość abstrakcyjnie. W praktyce chodzi o liczby – wagi – które model ustala podczas uczenia się. Parametr jest po prostu liczbą opisującą siłę powiązania między elementami danych. Im więcej parametrów, tym bardziej model może „dopasować się” do złożoności języka.
Jak wygląda proces trenowania?
Cały proces można opisać następującymi etapami:
- zebranie danych – teksty muszą być duże, różnorodne i jakościowe;
- przekształcenie tekstu na liczby – komputer nie rozumie słów, więc wszystko trzeba zamienić na tzw. wektory (czyli reprezentacje liczbowe);
- uczenie – model analizuje dane, uczy się zależności i dostosowuje parametry;
- walidacja – na tym etapie specjaliści sprawdzają, czy model nie „uczył się na pamięć”, lecz faktycznie potrafi tworzyć nowe, logiczne wypowiedzi;
- fine-tuning – czyli dostrajanie modelu do konkretnego celu, np. rozpoznawania ironii czy pisania w stylu prawniczym.
Ile to wszystko trwa?
Według szacunków OpenAI, trenowanie modelu GPT-3 trwało kilka miesięcy i kosztowało około 4,6 milionów dolarów. Wymagało to tysięcy jednostek GPU – czyli bardzo mocnych kart graficznych, które przetwarzają dane równolegle. Dla porównania nowoczesne modele mogą potrzebować nawet 10 razy więcej mocy i kosztów.

Najważniejsze informacje na temat treningu GPT-3. Źródło: lambda.ai/blog/demystifying-gpt-3
Czy modele mogą się „uczyć” po treningu?
Standardowy model LLM nie uczy się „w locie”. Nie zapamiętuje Twoich zapytań. Każda rozmowa to osobna sesja. Jednak coraz częściej stosuje się tzw. mechanizmy „uczenia z przykładów” (in-context learning), czyli zdolność do wyciągania wniosków z wcześniejszych fragmentów rozmowy – bez trwałego zapisywania wiedzy.
Dodatkowo wiele firm wprowadza systemy pamięci długoterminowej – czyli sposób przechowywania kontekstu rozmów – co umożliwia np. dostosowanie tonu wypowiedzi do stylu użytkownika.
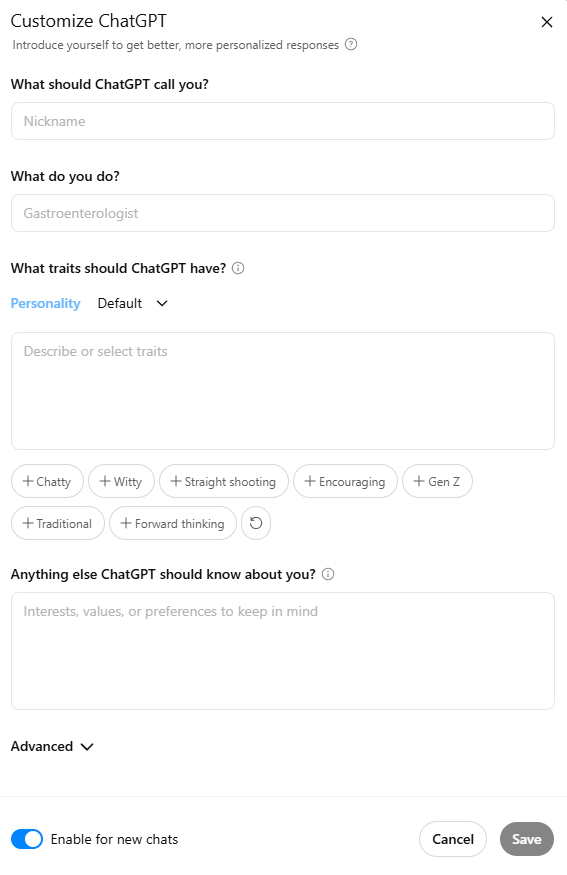
Opcja personalizacji ChatGPT – system pamięci długoterminowej.
Ale – co warto mocno podkreślić – modele nie „rozwijają się” same z siebie. Nie zmieniają swojej wiedzy automatycznie. Potrzebują do tego nowego procesu treningowego lub specjalnych narzędzi aktualizujących dane.
Z czym wiąże się korzystanie z LLM?
Każda technologia niesie za sobą konsekwencje – modele językowe nie są wyjątkiem. Z jednej strony – otwierają niesamowite możliwości:
- automatyczne tłumaczenia;
- generowanie dokumentów;
- wspomaganie nauki i pracy.
Z drugiej – pojawiają się istotne zagrożenia:
- dezinformacja – model może wygenerować logiczny, ale fałszywy tekst;
- uzależnienie od technologii – zamiast myśleć samodzielnie, ludzie pytają modeli;
- ryzyko naruszenia prywatności – jeśli dane wejściowe nie zostały odpowiednio przefiltrowane.
Dlatego każda instytucja wdrażająca LLM powinna mieć nie narzędzia, ale też zasady etyczne i kontrolne. A każdy użytkownik – zdrowy rozsądek.
Wpływ dużych modeli językowych na życie codzienne
Nie da się tego nie zauważyć. Duże modele językowe coraz częściej przestają być ciekawostką dla pasjonatów informatyki, a zaczynają być realnym narzędziem dla zwykłych ludzi. Od dziennikarza po nauczyciela, od studenta po lekarza – LLM trafiają do biur, szkół, mediów i urzędów.
Praca – czyli kto się boi automatyzacji?
Według raportu Goldman Sachs, nawet 300 milionów stanowisk pracy na świecie może zostać w jakimś stopniu zautomatyzowanych dzięki dużym modelom językowym. To nie znaczy, że 300 milionów ludzi straci pracę. Po prostu wiele zawodów się zmieni. Część zniknie. Część powstanie. Inne – będą wymagały nowych kompetencji.
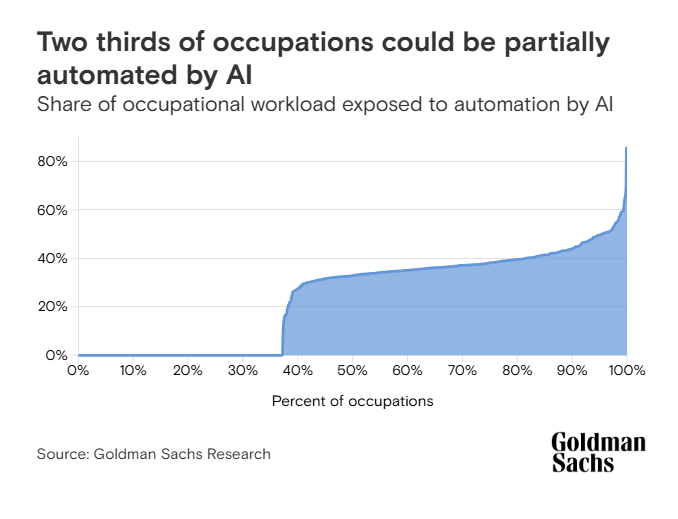
Goldman Sachs Research – statystyki.
Najbardziej narażone na automatyzację są zawody opierające się na:
- pisaniu tekstów (copywriting, podstawowe redakcje);
- wprowadzaniu danych (administracja, fakturowanie);
- analizie dokumentów (proste opinie prawne, streszczenia).
Ale pojawiają się też zupełnie nowe profesje:
- trenerzy modeli językowych;
- eksperci od „inżynierii zapytań” (czyli odpowiedniego formułowania poleceń);
- redaktorzy weryfikujący treści tworzone przez sztuczną inteligencję.
Edukacja – wyzwania i pokusy
Szkoły i uczelnie znalazły się na rozdrożu. Z jednej strony to ogromna szansa na dostęp do narzędzi wspierających naukę. Z drugiej – ryzyko, że uczniowie przestaną się uczyć samodzielnie.
Według badania Research Gate przeprowadzonego w 2024 roku, aż 39% studentów przyznało się do odpowiadania na pytania w trakcie tekstów przy pomocy LLM-ów, a 7% do pisania… całych prac licencjackich lub magisterskich.
To pokazuje skalę problemu – ale też potrzebę zmiany podejścia. Nie da się już „zakazać” LLM. Trzeba nauczyć ludzi współpracy z takimi rozwiązaniami. Zmienić metody oceniania. Uczyć krytycznego podejścia do informacji. Bo umiejętność sprawdzenia, czy wygenerowana treść ma sens – staje się równie ważna, jak jej stworzenie.
Badanie Timothy Paustian na temat wykorzystania modeli LLM przez studentów. Źródło: www.researchgate.net/publication/381370895_Students_are_using_large_language_models_and_AI_detectors_can_often_detect_their_use
Kultura i media – głos bez autora?
Literatura, muzyka, filmy, scenariusze. Wszystko to może być dziś tworzone lub współtworzone przez modele językowe. W 2023 roku ukazała się pierwsza powieść w Japonii, której autor przyznał się, że większość tekstu wygenerował model językowy – a on pełnił funkcję redaktora. Książka została uznana za jedno z bardziej interesujących debiutów roku.

Nagrodzona powieść wygenerowana w większości przez AI. Źródło: www.instagram.com/p/C2SzyJuoV99/
Tylko czy to jeszcze twórczość? Czy może już produkcja? Odpowiedź nie jest jednoznaczna. Modele nie mają intencji, nie mają przekazu, nie przeżywają tego, co piszą. Ale potrafią komponować. I to w sposób zaskakująco sprawny.
Media również zaczynają wykorzystywać LLM – niektóre agencje prasowe generują automatyczne streszczenia wydarzeń. Inne tworzą krótkie wiadomości ekonomiczne na podstawie danych giełdowych. Prędkość, z jaką można tworzyć treści, zmienia reguły gry. Pytanie tylko, co z jakością. Co z oryginalnością. Co z odpowiedzialnością.
Prawo i etyka – kto ponosi odpowiedzialność?
Tu sprawa się komplikuje. Bo jeżeli model wygeneruje treść, która narusza prawo, kto odpowiada?
- autor modelu?
- użytkownik, który wpisał polecenie?
- firma, która wdrożyła system?
Nie ma jednej odpowiedzi. Dlatego kraje i organizacje międzynarodowe próbują stworzyć regulacje. Unia Europejska przyjęła w 2024 roku „Akt o sztucznej inteligencji” (AI Act), który m.in. nakłada obowiązki przejrzystości na twórców dużych modeli językowych i nakazuje informowanie użytkowników, że komunikują się z systemem sztucznej inteligencji.
W kontekście naszego kraju portal rządowy Gov na temat Europejskiego AI Act podaje następujące informacje:
„12 lipca 2024 Rozporządzenie o sztucznej inteligencji (AI Act) zostało opublikowane w dzienniku urzędowym Komisji Europejskiej. Ten dokument określa ramy regulacyjne dla rozwoju, wdrażania i użytkowania sztucznej inteligencji na terenie Unii Europejskiej. Ministerstwo Cyfryzacji pracuje już nad projektem ustawy, która pozwoli na stosowanie AI Act w Polsce”. – Gov na temat AI Act.
W ciągu kolejnych lat możemy się tego spodziewać również w Polsce – AI Act dostosowany do naszego kraju znajdziesz na EUR-Lex.

AI Act – wyjaśnienie głównego celu. Źródło: www.gov.pl/web/cyfryzacja/europejski-ai-act-opublikowany
Modele językowe w Polsce
Polskie uczelnie pracują nad własnymi modelami językowymi przeszkolonymi na polskim korpusie językowym. W 2023 roku zespół z Politechniki Wrocławskiej stworzył model „Herbert” – pierwszy LLM zoptymalizowany pod język polski i dane lokalne. Pojawiają się też inicjatywy komercyjne i edukacyjne – wspierające uczniów, nauczycieli i przedsiębiorców.
Ale przed nami długa droga. Potrzebujemy inwestycji, badań, a przede wszystkim zaufania społecznego. LLM nie są celem samym w sobie – są narzędziem. Od nas zależy, jak je wykorzystamy.
Trudno przewidzieć przyszłość. Ale jedno jest pewne – duże modele językowe już z nami są. Będą coraz lepsze, szybsze, bardziej zniuansowane. Z czasem nauczą się też „uczuć” – oczywiście tylko w sensie językowym. Ale ich wpływ na gospodarkę, edukację, media i społeczeństwo będzie rósł.