
Plagiat w SEO – o czym trzeba wiedzieć?
Według danych Jednolitego Systemu Antyplagiatowego, w 2022 roku zaledwie 1,7% prac dyplomowych wzbudziło podejrzenie plagiatu – trzy lata wcześniej było to aż 2,5%. Spadek widoczny w środowisku akademickim nie ma jednak przełożenia na internet, gdzie problem powielania treści pozostaje powszechny, ale trudniej wykrywalny. Pozycjonowanie to już nie tylko unikanie kopiowania słowo w słowo – algorytmy analizują powtarzalność konstrukcji, stylów i danych w celu eliminowania treści wtórnych. Jeśli publikujesz materiały bez weryfikacji ich oryginalności, ryzykujesz karą ręczną, ale także trwałe obniżenie pozycji całej witryny (ze względu na penalizacje Google).
Plagiat – definicja nie jest taka oczywista, jak się wydaje
Najprostsza definicja plagiatu wciąż funkcjonuje w świadomości wielu osób: ktoś przepisuje tekst z innej strony i publikuje jako własny. Owszem, to klasyczny przykład. Ale problem jest znacznie szerszy.
W praktyce występują różne formy zawłaszczenia treści, z których wiele osób nawet nie zdaje sobie sprawy. Nie zawsze trzeba coś skopiować dosłownie. Wystarczy wykorzystanie cudzego pomysłu, układu myślowego, konstrukcji argumentacyjnej lub danych, bez odniesienia do pierwotnego autora.
Według definicji ustawowej (Ustawa o prawie autorskim i prawach pokrewnych bazującej na informacjach sip.lex.pl), plagiat to bezprawne przywłaszczenie autorstwa cudzego utworu albo wprowadzenie w błąd co do autorstwa – niezależnie od formy i okoliczności.
Ustawa o prawie autorskim i prawach pokrewnych – sip.lex.pl. Źródło: sip.lex.pl/akty-prawne/dzu-dziennik-ustaw/prawo-autorskie-i-prawa-pokrewne-16795787
SEO posługuje się własnymi kategoriami
W kontekście wyszukiwarek definicja plagiatu zyskuje dodatkowy wymiar. Nie chodzi już tylko o autorstwo, ale o unikalność. Treść powielona, nawet legalnie, przestaje być wartościowa z punktu widzenia algorytmów Google. Strona traci na znaczeniu, jeśli prezentuje te same informacje, które są już dostępne w internecie w niemal identycznej formie.
Rodzaje plagiatu w świecie SEO
Podział na plagiat jawny i plagiat ukryty to najczęściej stosowane rozróżnienie w środowisku content marketingowym. Jednak w rzeczywistości form jest znacznie więcej.
Plagiat jawny – nic do ukrycia, wszystko do stracenia
To najbardziej oczywisty i najbardziej ryzykowny przypadek. Całe akapity przepisane z innych stron, artykuły bez jakiejkolwiek ingerencji własnej. Algorytmy wyszukiwarek identyfikują takie duplikaty szybko. W dodatku wiele serwisów chroni swoje treści systemami antyplagiatowymi (np. Copyscape, Siteliner czy Plagiarism Detector), działającymi podobnie jak systemy akademickie do wykrywania nieuczciwości.
Efekt? Strona, która zawiera plagiat jawny, może zostać uznana za nieoryginalną. Zniknięcie z indeksu wyszukiwarki to tylko jeden z możliwych scenariuszy. Utrata zaufania użytkowników i partnerów – kolejny.
Więcej o plagiacie jawnym i ukrytym znajdziesz w materiale pomocniczym z serwisu GOV.

Plagiat jawny i ukryty – definicje.
Plagiat ukryty – bardziej wyrafinowany, ale nie mniej szkodliwy
W tym przypadku nie kopiujesz, tylko „inspirujesz się”, zmieniasz szyk zdania, używasz synonimów, ale… nie tworzysz niczego nowego. Nie wprowadzasz własnych danych, opinii ani interpretacji.
Algorytmy analizujące tekst nie działają jedynie na poziomie słów. Wchodzą głębiej – analizują strukturę, logikę, sposób budowania przekazu. W efekcie nawet lekko przepisany tekst może zostać rozpoznany jako plagiat ukryty i potraktowany jak treść o znikomej wartości dodanej.
Plagiat automatyczny – problem ery narzędzi tekstowych
Choć systemy automatyczne nie przepisują tekstów z internetu, mogą generować fragmenty przypominające treści już istniejące. Zdarza się, że setki użytkowników otrzymują zbliżone konstrukcje zdań, podobny tok argumentacji i identyczne zwroty. Gdy te teksty trafiają w sieć – zaczynają się nakładać.
Problem narasta przy masowym wykorzystywaniu tych narzędzi bez redakcji i przekształcenia treści. Powstają wtedy teksty pozornie oryginalne, ale niemające żadnej merytorycznej wartości – algorytmy Google nazywają je „thin content”.
Plagiat w SEO – jakie są konsekwencje?
Google nie wydaje wyroków, ale działa stanowczo. Treści uznane za powielone, słabe jakościowo lub nieoryginalne podlegają tzw. filtracji jakościowej.
Oznacza to:
- spadek pozycji w wynikach wyszukiwania – najczęstszy i najbardziej odczuwalny efekt;
- pominięcie treści podczas indeksowania – Google nie uwzględnia tekstu, który uzna za zduplikowany;
- ryzyko nałożenia filtra ręcznego – zespół Google ocenia jakość strony i podejmuje decyzję o ograniczeniu jej widoczności;
- utrata zaufania wśród odbiorców – szczególnie w branżach, gdzie treść stanowi podstawę wartości strony.
Aby zweryfikować stan indeksacji witryny, zaloguj się do GSC i wejdź w sekcję Indexing → Pages.
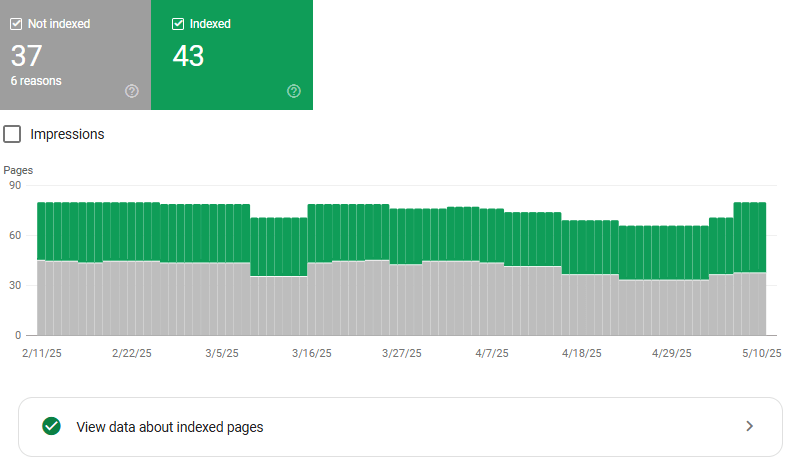
Stan indeksowania w GSC.
Jak rozpoznać plagiat w treści SEO?
Dostępne są liczne narzędzia umożliwiające analizę zawartości:
- Plagscan – narzędzie akademickie, które dobrze radzi sobie również z treściami SEO;
- Copyscape – szybka analiza online, idealna do sprawdzania tekstów publikowanych w sieci;
- Siteliner – bada duplikaty wewnętrzne na Twojej stronie, czyli identyczne fragmenty powielone na różnych podstronach;
- Narzędzia wbudowane w platformy SEO (Senuto, Surfer SEO, Grammarly) – często wyposażone w moduły sprawdzające unikalność.
Analiza plagiatu w narzędziu Grammarly.
Kiedy cytat nie jest plagiatem?
Cytowanie nie jest złem samym w sobie. W polskim prawie funkcjonuje pojęcie dozwolonego użytku osobistego oraz prawa cytatu. Można korzystać z fragmentów cudzych tekstów, pod warunkiem spełnienia kilku wymagań:
- autor cytowanego fragmentu jest jasno wskazany – imię, nazwisko lub nazwa instytucji;
- cytat jest fragmentem większej całości – nigdy nie dominuje w treści;
- tekst, w którym pojawia się cytat, wnosi nowe treści – opinie, interpretacje, dane autorskie.
Bez spełnienia tych warunków każdy cytat staje się plagiatem ukrytym – a więc poważnym błędem SEO.
Jak Google traktuje plagiat w praktyce?
Google już dawno przestało być wyszukiwarką opartą na prostym dopasowaniu słów. Dzisiejsze algorytmy działają kontekstowo, semantycznie i predykcyjnie. Dlatego plagiat w SEO nie jest analizowany na poziomie „czy ktoś przepisał dokładnie to samo zdanie”, ale znacznie głębiej.
Wyszukiwarka korzysta z następujących komponentów:
- Panda – filtr jakościowy skupiony na treściach o niskiej wartości, duplikatach, zbyt dużej liczbie reklam, słabej strukturze;
- Hummingbird – analizuje kontekst, intencję użytkownika, a nie tylko dopasowanie słów kluczowych;
- Helpful Content Update – aktualizacja z 2022 roku, która promuje autentyczne, oryginalne, napisane dla człowieka treści.
Właśnie ta ostatnia zmiana najbardziej uderza w plagiat ukryty. Jeśli tekst nie wnosi nic nowego, jest wtórny, przypomina inne publikacje – nie uzyska dobrej widoczności, bez względu na techniczne SEO.
Statement Google na temat Helpful Content Update jest jasny:
„Nieustannie pracujemy nad tym, aby wyszukiwarka Google skuteczniej udostępniała użytkownikom przydatne informacje. W związku z tym wprowadzamy tzw. aktualizację dotyczącą przydatnej treści, która jest częścią naszych szerszych działań zmierzających do tego, aby w wynikach wyszukiwania użytkownicy widzieli więcej oryginalnych i przydatnych treści tworzonych dla nich przez innych użytkowników”. – Centrum wyszukiwarki Google.
W środowisku optymalizacyjnym istnieje też wyraźne rozróżnienie między:
- duplicate content wewnętrznym – występuje, gdy ta sama treść znajduje się w kilku miejscach tej samej domeny (np. wersja z „www” i bez „www”, z parametrami i bez);
- duplicate content zewnętrznym – dotyczy sytuacji, gdy treść pojawia się w identycznej lub bardzo podobnej formie na innych domenach.
Oba przypadki wpływają na widoczność. Google sam wybierze wersję, którą uzna za najbardziej autorytatywną, resztę może całkowicie zignorować.
Czy da się chronić stronę przed plagiatem?
Najskuteczniejszą ochroną jest inwestycja w unikalne, merytoryczne teksty. Jeśli tworzysz treści, które zawierają:
- analizę własnych danych lub obserwacji;
- opinie oparte na doświadczeniu;
- opisy procesów, których nie znajdzie się w innych źródłach;
- własny język i styl – rozpoznawalny i autentyczny;
… to jesteś bezpieczny. Taka treść sama w sobie jest trudna do zduplikowania i łatwa do obrony, zarówno pod kątem prawnym, jak i SEO.
Narzędzia zabezpieczające witrynę
Oprócz sprawdzania treści pod kątem unikalności, warto też zadbać o to, aby Twoje teksty nie były kopiowane przez innych:
- Copysentry – automatyczne monitorowanie sieci pod kątem powielania Twoich tekstów;
- Google Alerts – darmowe narzędzie pozwalające śledzić, czy Twoje frazy pojawiają się na innych stronach;
- DMCA Protection Badge – znak informujący, że Twoja strona jest monitorowana pod kątem naruszeń autorskich.
Plagiat a wiarygodność strony
Odwiedzający wchodzi na stronę z konkretnym oczekiwaniem: chce przeczytać coś, czego jeszcze nie zna. Jeśli dostaje powielony artykuł, który widział już gdzieś indziej, traci zaufanie. A razem z nim spada:
- średni czas spędzony na stronie;
- liczba aktywnych użytkowników;
- działania podjęte na stronie (Event count);
- liczba odwiedzanych podstron;
- wskaźnik powracających użytkowników.
Powyższe statystyki zweryfikujesz w Google Analytics 4 w sekcji Reports.
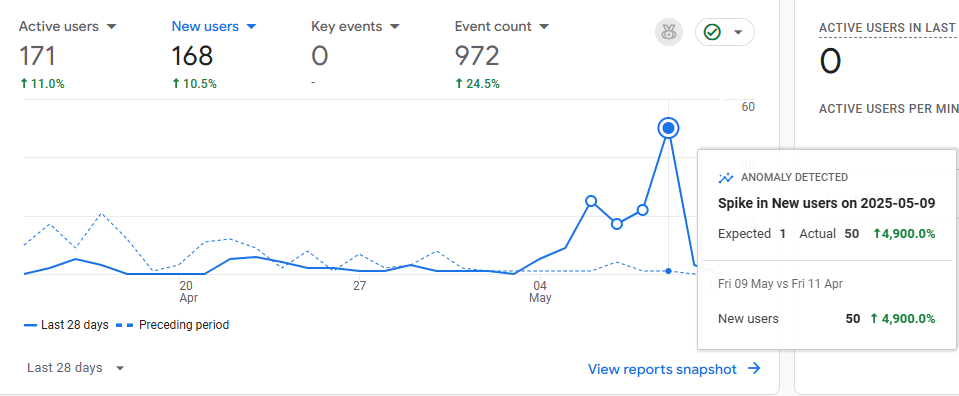
Analiza istotnych statystyk w GA4.
Jak unikać plagiatu tworząc treści SEO?
W celu unikania plagiatu podczas tworzenia treści SEO:
- pisz na podstawie własnych doświadczeń – nawet techniczne tematy można przedstawić przez pryzmat konkretnego przypadku;
- stosuj dane źródłowe – statystyki, raporty branżowe, wyniki badań zawsze podnoszą wartość tekstu;
- opisuj procesy i metody działania, nie tylko definicje – pomagają tworzyć unikalną strukturę treści;
- używaj własnego stylu – charakterystyczny język jest trudniejszy do skopiowania i łatwiejszy do zapamiętania.
Jakie narzędzia pomogą wykryć plagiat w treści SEO?
Nie ma treści odpornej na błędy, ale są sposoby, aby je zawczasu wyłapać.
Plagscan
Dobrze znane w środowisku naukowym, ale świetnie radzi sobie także z treściami internetowymi. Analizuje strukturę tekstu i porównuje z zawartością zasobów sieciowych. Dostępny w wersji darmowej z limitem słów.
Plagscan do weryfikacji plagiatu. Źródło: www.plagscan.com/en/
Copyscape
Klasyka branży SEO. Wystarczy wkleić link lub tekst, żeby sprawdzić, czy treść pojawia się gdzieś indziej. Wersja premium pozwala porównywać większe ilości danych i daje dokładniejsze wyniki.
Narzędzie Copyscape. Źródło: www.copyscape.com
Siteliner
Służy do sprawdzania duplikatów wewnętrznych w obrębie jednej domeny. Jeśli masz duży serwis z wieloma podstronami, okazuje się bardzo pomocne. Dzięki temu narzędziu dowiesz się, gdzie powielasz własne treści – często zupełnie nieświadomie.

Siteliner – do znalezienia zduplikowanego contentu. Źródło: www.siteliner.com
Czy plagiat SEO podlega odpowiedzialności prawnej?
W polskim systemie prawnym plagiat jest czynem zabronionym. Zgodnie z Ustawą o prawie autorskim i prawach pokrewnych:
- autor ma prawo do ochrony swojej twórczości niezależnie od formy publikacji (druk, internet, materiały wewnętrzne);
- plagiator może zostać pociągnięty do odpowiedzialności cywilnej (roszczenia odszkodowawcze) i karnej (nawet do 3 lat pozbawienia wolności).
Jeśli prowadzisz stronę firmową i publikujesz cudze treści jako własne – narażasz nie tylko siebie, ale też markę, którą reprezentujesz.

Ustawa o prawie autorskim i prawach pokrewnych z dnia 4 lutego 1994 r. Źródło: isap.sejm.gov.pl/isap.nsf/download.xsp/WDU19940240083/U/D19940083Lj.pdf
Jak sprawdzić, czy Twój tekst nie jest plagiatem? Checklista!
Czas na praktyczne podsumowanie – krótko, konkretnie, na bazie rzeczywistych potrzeb:
- Czy każda część tekstu wnosi coś nowego i oryginalnego?
- Czy w treści znajdują się dane lub elementy unikalne (np. autorskie spostrzeżenia)?
- Czy korzystałeś z cudzych źródeł? Jeśli tak – czy je oznaczyłeś?
- Czy porównałeś tekst w narzędziu typu Copyscape lub Plagscan?
- Czy redagowałeś treść, nie tylko przepisywałeś lub parafrazowałeś?
- Czy unikasz „maszynowego” języka (ciągi ogólników, brak emocji, powtórzenia)?
Jeśli odpowiedzi są twierdzące – jesteś na dobrej drodze. Jeśli nie – jeszcze nic straconego. Każdy tekst można poprawić.
Chcesz tworzyć treści, które realnie wspierają pozycjonowanie i są zgodne z wytycznymi wyszukiwarek? Skorzystaj z doświadczenia agencji Webmetric – pracujemy analitycznie, transparentnie i bez kompromisów jakościowych. Zadzwoń lub napisz do nas, aby ustalić szczegóły współpracy i otrzymać precyzyjne wsparcie dopasowane do Twoich potrzeb.
FAQ – najczęściej zadawane pytania o plagiat w SEO
Jakie są najczęstsze pytania i odpowiedzi na temat plagiatu w SEO?
Czy plagiat może obniżyć pozycję mojej strony w Google?
Tak. Jeśli Google wykryje, że treść jest powielona lub ma znikomą wartość autorską, może ograniczyć jej widoczność w wynikach lub całkowicie ją zignorować.
Czy parafraza chroni przed uznaniem treści za plagiat?
Nie zawsze. Jeśli tekst opiera się na cudzym układzie logicznym, strukturze lub danych, nawet przy zmienionych słowach może zostać uznany za plagiat ukryty.
Jakie narzędzia warto wykorzystać do sprawdzania unikalności treści?
Skorzystaj z Plagscan, Copyscape lub Siteliner. Pozwalają one przeanalizować zarówno powielenia zewnętrzne, jak i wewnętrzne oraz wychwycić podobieństwa w strukturze tekstu.
Czy cytowanie źródeł eliminuje ryzyko plagiatu?
Cytat nie narusza praw autorskich, jeśli stanowi fragment większej treści i zawiera poprawnie oznaczone źródło. Należy zachować równowagę między treścią własną a cytowaną.
Czy treści generowane przez AI mogą zostać uznane za plagiat?
Tak, jeśli są publikowane bez edycji i zawierają powtarzalne struktury znane już wyszukiwarce. AI generuje treści statystycznie podobne do tych, które już istnieją, co zwiększa ryzyko ich zakwalifikowania jako wtórne.
Jak odróżnić inspirację od plagiatu?
Inspiracja zakłada własny wkład i przekształcenie informacji. Plagiat występuje, gdy kopiujesz cudzy tok myślowy, dane lub narrację, nie tworząc nowej wartości.
Czy powielanie własnych tekstów na różnych podstronach też jest plagiatem?
Z perspektywy SEO – tak. Powtarzające się treści w obrębie tej samej domeny są traktowane jako duplicate content i obniżają efektywność indeksowania.













![Algorytmy Google – rodzaje i działanie [2026]](https://webmetric.com/wp-content/uploads/2025/11/algorytmy-google.jpg)
