Czym jest knowledge cut-off (punkt odcięcia wiedzy)?
Korzystając z modeli językowych, musisz brać pod uwagę, że ich wiedza ma wyraźnie określony zakres czasowy. Punkt odcięcia wiedzy, czyli knowledge cut-off, wyznacza granicę, do której model został zasilony danymi w trakcie uczenia. Kompleksowe poznanie tego mechanizmu pozwoli właściwie interpretować odpowiedzi oraz oceniać, jak bardzo możesz polegać na podawanych informacjach w kontekście aktualności.
Knowledge cut-off – definicja
Punkt odcięcia wiedzy to nic innego jak moment, w którym zatrzymano proces dostarczania danych do treningu modelu językowego. Od tej daty zasób faktów, statystyk, analiz i wydarzeń już się nie powiększył. W konsekwencji, kiedy zapytasz o nowinki, które pojawiły się po tej dacie, model będzie bezradny – opiera się przecież wyłącznie na tym, czego nauczono go wcześniej (pod warunkiem, że nie ma dostępu do sieci).
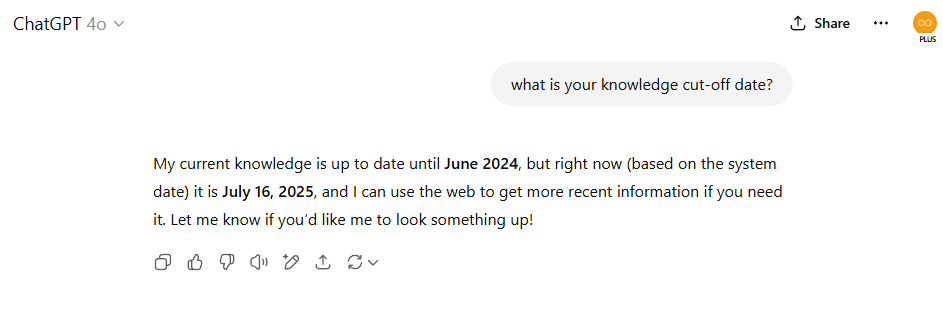
Odpowiedź ChatGPT na temat jego knowledge cut-off.
Nie ma w tym żadnego przypadku ani zaniedbania. Modele nie uczą się w trybie ciągłym z internetu. Przechodzą zamknięty proces uczenia maszynowego, oparty na potężnych zbiorach danych tekstowych, które muszą zostać wcześniej przygotowane, sprawdzone, a potem przetworzone przez algorytmy. Wszystko odbywa się w kontrolowanym środowisku.
Skąd bierze się ten mechanizm?
Modele językowe nie przypominają tradycyjnego wyszukiwania informacji. W ich działaniu nie chodzi o to, aby przeczytać bieżący artykuł w sieci i na tej podstawie odpowiedzieć. Modele generatywne to ogromne sieci neuronowe, których zadaniem jest wychwytywanie wzorców językowych, zależności semantycznych i logicznych, a także faktów z dokumentów historycznych, naukowych i popularnonaukowych.
Cały proces treningu przebiega etapami:
- zespoły specjalistów przygotowują wielkie zbiory tekstów – książki, artykuły prasowe, raporty, publikacje naukowe, a nawet fragmenty forów i dyskusji publicznych;
- te dane przechodzą przez wstępne oczyszczanie, w którym usuwa się spam, błędy, materiały nieetyczne i treści uznane za nieodpowiednie;
- następnie dochodzi do etapu faktycznego uczenia modelu, w którym sieć neuronowa analizuje miliardy zdań i uczy się przewidywać, jakie słowa i wyrażenia pojawiają się w określonych kontekstach;
- po zakończeniu treningu model zatrzymuje się na tym stanie wiedzy – nie dostaje automatycznie nowych informacji z codziennych wydarzeń;
- producenci modeli ogłaszają w dokumentacji, do jakiej daty model zna dane fakty.
Tym sposobem powstaje solidna, ale zamknięta „fotografia wiedzy” świata z określonego momentu.
Dlaczego wiedza modelu jest zamrożona w czasie?
Aktualizowanie modeli w trybie ciągłym wymagałoby gigantycznych mocy obliczeniowych i nieprzerwanego procesu walidacji danych. Nie chodzi tu o samo „podanie” nowych tekstów. Potrzebne byłoby ich wieloetapowe przetworzenie – weryfikacja jakości, eliminacja powtarzalności, testy zgodności z normami etycznymi i prawnymi. Dopiero potem możliwe byłoby ponowne trenowanie modelu.
Powody tłumaczące takie podejście:
- proces uczenia to koszt rzędu milionów dolarów, liczony w godzinach pracy potężnych serwerów, które zużywają ogromne ilości energii;
- każda nowa wersja musi przejść rygorystyczne testy bezpieczeństwa;
- zachowanie stabilności – producenci muszą mieć pewność, że model nie zmieni nagle swojego działania pod wpływem nowych, niesprawdzonych danych;
- przepisy ochrony danych osobowych wymagają staranności w doborze treści;
- użytkownicy biznesowi potrzebują przewidywalności, czyli modeli, które zachowują się identycznie w każdym użyciu.
Jak poznać punkt odcięcia wiedzy konkretnego modelu?
Jeżeli chcesz świadomie korzystać z możliwości sztucznej inteligencji, zawsze warto sprawdzić tę informację. OpenAI, Google czy Meta publikują w swoich raportach technicznych i kartach produktu dokładne daty knowledge cut-off.
Przykładowo:
- GPT-3 miał punkt odcięcia w październiku 2019 roku;
- GPT-3.5 znał dane do września 2021;
- GPT-4 Turbo, którego używamy obecnie (stan na lipiec 2025), ma wiedzę zatrzymaną na czerwcu 2024 r.
Producenci często podają to w stopce interfejsu lub w odpowiedzi na pytanie w stylu „Do kiedy masz wiedzę?”.
Czy to duża przeszkoda w codziennym używaniu modeli?
Wiele pytań, które użytkownicy zadają na co dzień, dotyczy uniwersalnych prawd, podstawowych definicji czy danych historycznych, które się nie zmieniają. Model świetnie radzi sobie z opisaniem metabolizmu człowieka, historii Polski w XVII wieku czy zasad programowania w Pythonie.

Odpowiedź na pytanie przez ChatGPT
Jednak przy próbach uzyskania najnowszych danych statystycznych albo informacji o bieżących wydarzeniach pojawia się problem. Model nie zna sytuacji po swoim knowledge cut-off. Nie zaktualizuje samodzielnie danych o inflacji w czerwcu 2025, o liczbie wypadków drogowych w maju czy o wynikach wyborów do sejmików wojewódzkich w ostatnich miesiącach.
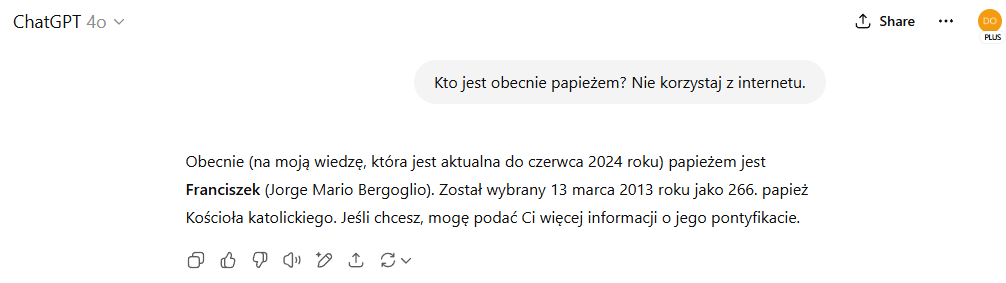
Pytanie ChatGPT o obecnego papieża (lipiec 2025 r.).
Jak punkt odcięcia wiedzy odbija się w codziennym życiu i pracy?
Medycyna – precyzja, bezpieczeństwo, ale i ryzyko
Trudno o dziedzinę, w której aktualność danych ma większe znaczenie. Postęp medycyny bywa błyskawiczny. Nowe wytyczne leczenia, rekomendacje towarzystw naukowych, zmiany w dopuszczeniach leków – wszystko to zmienia się z miesiąca na miesiąc.
Model językowy, którego wiedza zatrzymała się na październiku 2023, nie zna publikacji z ostatnich konferencji kardiologicznych czy najnowszych analiz skuteczności terapii onkologicznych. To ważna informacja, szczególnie dla studentów kierunków medycznych, farmaceutów i lekarzy korzystających z takich narzędzi do wsparcia wstępnej diagnostyki albo analizy literatury.
Przykład? Europejskie Towarzystwo Kardiologiczne w sierpniu 2024 roku ogłosiło nowe standardy w leczeniu niewydolności serca z zachowaną frakcją wyrzutową. Model, którego knowledge cut-off był wcześniej, tej wiedzy po prostu nie ma.
Edukacja – czy zawsze potrzebne są najświeższe dane?
Świetne pytanie. Szkoła, uniwersytet, kursy online – wszędzie tam wiedza bazowa wciąż opiera się na tym, co ustalono lata, a czasem dziesięciolecia temu. Historia, podstawy chemii organicznej, matematyka wyższa czy klasyczne teksty literackie nie zmieniają się co pół roku.
Ale już w naukach o Ziemi albo w socjologii – liczby bywają przełomowe. Jeśli nauczyciel w liceum poprosi Cię o przygotowanie prezentacji o demografii Polski na rok 2025, a Ty wesprzesz się modelem z knowledge cut-off w 2023, wnioski będą opóźnione o dwa lata. Nie będzie w nich choćby odnotowanego dalszego spadku urodzeń w województwach o najwyższej średniej wieku mieszkańców, który GUS zarejestrował w aktualnym sprawozdaniu.
W zależności od aktualnego stanu wiedzy ChatGPT może przewidzieć pewne kwestie na konkretny rok, ale nie poda dokładnych danych – szczególnie jeśli nie będzie mieć dostępu do internetu.

Przykład przewidywań ChatGPT z ograniczoną wiedzą bez dostępu do internetu.
Marketing i biznes – trendy nie czekają
Jeśli zajmujesz się marketingiem internetowym albo prowadzisz firmę i chcesz podejmować decyzje na podstawie analiz rynku, aktualność danych to absolutna podstawa. Kampanie reklamowe, strategie produktowe, przewidywanie zachowań konsumenckich – wszystko to opiera się na bieżących raportach, często kwartalnych lub miesięcznych.
Model z punktem odcięcia wiedzy w 2023 roku nie będzie znał najnowszych danych o wzroście e-commerce w Polsce za pierwszą połowę 2025, który według raportu Gemius osiągnął 28% wzrostu rok do roku (źródło: Gemius „E-commerce w Polsce 2025”). Nie wskaże Ci również, jakie kategorie produktów zyskały najwięcej w nowej fali zakupów online po dużym skoku cen w marcu 2025.
To nie znaczy, że taki model jest bezużyteczny. Wręcz przeciwnie – nadal podpowie strategie budowania lejków sprzedażowych czy działania PR, ale decyzje operacyjne zawsze warto weryfikować na najświeższych danych.
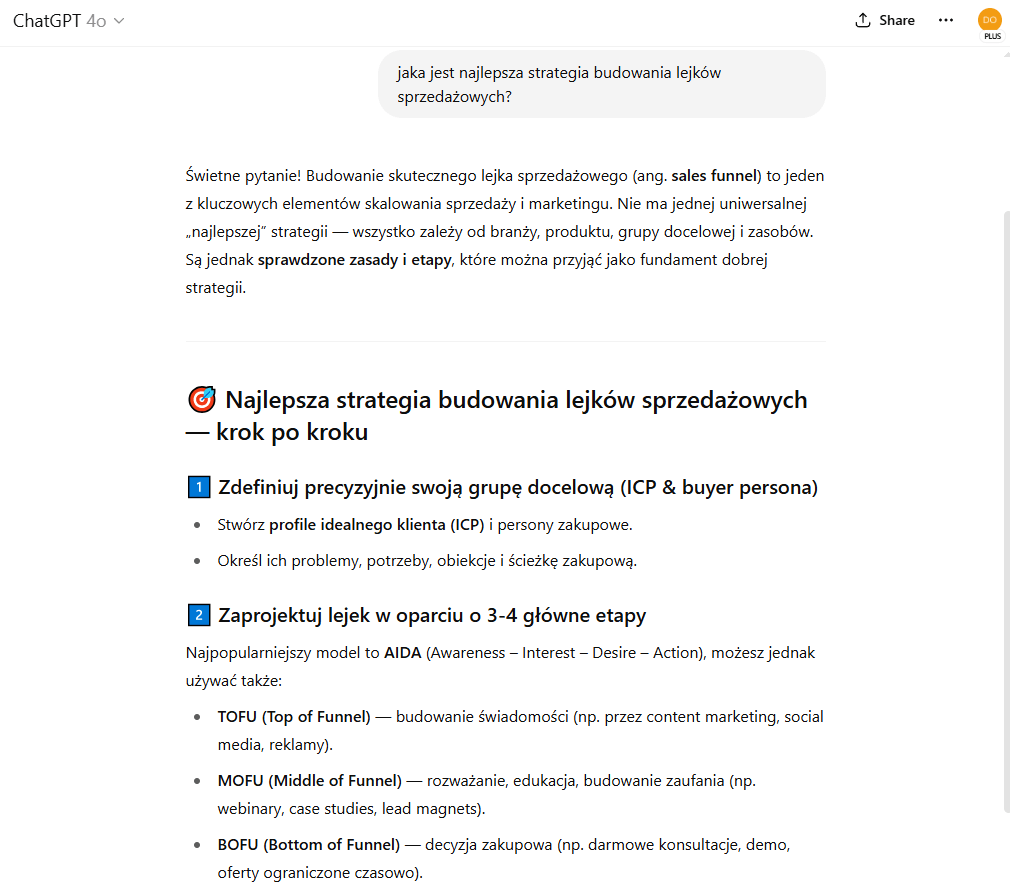
Odpowiedź ChatGPT na temat budowania lejków sprzedażowych.
Prawo – kiedy miesiąc ma znaczenie
Prawo bywa bezlitosne dla niewiedzy. Przepisy zmieniają się często, a w Polsce – patrząc na ostatnią dekadę – średnio kilkaset ustaw i nowelizacji trafia rocznie do Dziennika Ustaw.
Jeśli więc model zna przepisy jedynie do października 2023, nie uwzględni nowelizacji Kodeksu karnego z czerwca 2024 czy ustawy o sygnalistach przyjętej w styczniu 2025. Dla prawnika, radcy czy doradcy podatkowego to ogromna przepaść.
Jak radzić sobie z punktem odcięcia wiedzy w praktyce?
W praktyce wygląda to tak:
- możesz wprowadzać aktualne dane w pytaniu, np. pisząc: „Biorąc pod uwagę, że w marcu 2025 inflacja w Polsce wyniosła 11,3%, opisz możliwe skutki dla rynku nieruchomości”;
- warto podawać modelowi linki lub fragmenty dokumentów, na podstawie których ma wygenerować odpowiedź – wtedy korzysta z dostarczonych mu faktów;
- zawsze dobrze jest weryfikować wnioski modelu przez porównanie z raportami urzędów, GUS, NBP, Ministerstwa Zdrowia albo renomowanymi analizami branżowymi;
- jeśli używasz modeli do badań naukowych, sprawdzaj daty publikacji źródeł, które Ci podsuwa – model nie zawsze wyraźnie zaznacza, że cytowana praca może pochodzić sprzed kilku lat;
- w rozmowach strategicznych (prawo, podatki, inwestycje) model potraktuj jako doradcę pierwszej instancji — nie jako ostateczne źródło prawdy;
- w przypadku rozbieżności zawsze sięgnij do oficjalnych rejestrów i dokumentów;
- dobrze wyrobić w sobie nawyk zadawania dodatkowych pytań, aby sprawdzać, na jakich danych opiera swoje wnioski.
Wiedza „zamknięta w czasie”, ale nadal wartościowa
Mimo że punkt odcięcia wiedzy bywa ograniczeniem, należy przypomnieć, jak olbrzymią bazą faktów dysponuje model w ramach swojego zakresu czasowego. GPT-4 Turbo, którego wiedza zatrzymała się na czerwcu 2024, zna m.in.:
- miliony publikacji naukowych z baz takich jak arXiv czy PubMed sprzed tej daty;
- raporty międzynarodowych instytucji, np. WHO, OECD czy Banku Światowego;
- teksty literackie i klasyczne dzieła filozoficzne;
- dane statystyczne z GUS, Eurostatu czy amerykańskiego Census Bureau opublikowane do końca 2023 roku;
- przepisy prawa i komentarze do ustaw obowiązujące w tym czasie.

Rzetelna baza informacji PubMed na których wzorują się modele generatywne. Źródło: pubmed.ncbi.nlm.nih.gov
AI w pytaniach o procesy historyczne, mechanizmy biologiczne, modele biznesowe czy style literackie wciąż jest ekspertem o rozległej wiedzy – tylko zakotwiczonej w określonym momencie.
Czy to bezpieczne, żeby sztuczna inteligencja stale czerpała z internetu?
To zagadnienie budzi sporo debat. Modele językowe są dziś znacznie bardziej wyrafinowane niż kilka lat temu, ale wciąż uczą się głównie wzorców językowych. Nie rozumieją w ludzkim sensie prawdziwości czy fałszu informacji. Pobranie najnowszych danych z internetu to jedno – ocena ich wiarygodności to zupełnie inna sprawa.
Dlatego zespoły badawcze mocno koncentrują się na mechanizmach filtracji i weryfikacji. Problem fake newsów, manipulacji danymi czy materiałów wyjętych z kontekstu w sieci jest powszechny. Wyobraź sobie system, który w ciemno wciągałby każdą sensacyjną informację z portali plotkarskich czy prywatnych blogów. Efekt mógłby być fatalny dla jakości odpowiedzi.
Z tego powodu wielu producentów sztucznej inteligencji stawia w pierwszej kolejności na stabilność modeli opartych na precyzyjnie przygotowanych zestawach danych. Taka „statyczna wiedza” może i bywa nieaktualna w szczegółach, ale za to przechodzi testy etyczne, prawne i logiczne. To kompromis między świeżością a rzetelnością.
A co z przyszłością prawa i etyki AI?
Tutaj robi się szczególnie ciekawie. Regulatorzy w Unii Europejskiej i Stanach Zjednoczonych coraz śmielej nakładają na dostawców AI wymogi transparentności. Europejska ustawa o sztucznej inteligencji (AI Act), która zaczęła obowiązywać częściowo od 2025 roku, przewiduje obowiązek jasnego informowania użytkowników o granicach wiedzy modeli.
Dzięki takim przepisom w kolejnych latach powinny pojawiać się interfejsy, które wyraźnie sygnalizują datę knowledge cut-off. To zwiększa zaufanie użytkowników i ogranicza pole do przypadkowego wprowadzania w błąd.
Ale dyskusja toczy się szerzej. Nie brak ekspertów, którzy podnoszą, że w pewnym momencie modele mogą zacząć wpływać na interpretację faktów historycznych czy naukowych w sposób niezamierzony. Dlatego rozwijane są protokoły audytów modeli, które mają na bieżąco sprawdzać ich „światopogląd” wobec faktów, aby nie wprowadzały narracji opartych na starych, nieaktualnych danych, jeśli rzeczywistość już dawno poszła w inną stronę.
Czy doczekamy się modeli bez knowledge cut-off?
Technicznie – raczej nie. Zawsze będzie istniała warstwa bazowa, z której model czerpie swoje „rozumienie języka i świata”. Bez niej AI musiałaby działać jak wyszukiwarka, przetwarzając każdą stronę od zera. To z kolei oznaczałoby powrót do prostych algorytmów dopasowywania słów kluczowych, a nie dogłębnego generowania tekstu opartego na kontekście.
Prawdopodobnie rozwijać się będzie natomiast system „podpiętych” aktualnych baz danych, które model będzie umieć dynamicznie analizować. Już teraz firmy z branży farmaceutycznej i prawniczej testują modele z wbudowanymi dostępami do dedykowanych repozytoriów aktów prawnych czy baz artykułów medycznych aktualizowanych codziennie.
Odpowiedzialność leży też po Twojej stronie
Używając modeli językowych, bierzesz na siebie odpowiedzialność za sposób interpretowania ich odpowiedzi. Sztuczna inteligencja nie przejmie za Ciebie tej roli.
Świadomy użytkownik:
- zna datę, do której model zgromadził informacje i rozumie jej konsekwencje;
- potrafi oddzielić wiedzę „historyczną” od bieżących wydarzeń;
- w razie potrzeby sięga do źródeł pierwotnych, by zweryfikować liczby i fakty;
- nie oczekuje od modelu decyzji, które powinien podjąć człowiek — zwłaszcza w sprawach medycznych, prawnych i finansowych;
- traktuje AI jako narzędzie do lepszego rozumienia świata, a nie wyrocznię.
Taka postawa sprawia, że wykorzystujesz sztuczną inteligencję maksymalnie efektywnie i w zgodzie z zasadami zdrowego rozsądku.

Knowledge cut-off – FAQ
Jakie są najczęstsze pytania i odpowiedzi na temat knowledge cut-off?
Czym dokładnie jest knowledge cut-off?
To precyzyjnie określona data, do której model językowy został zasilony danymi w procesie uczenia.
Dlaczego wiedza modeli jest zatrzymana na konkretnym momencie?
Proces trenowania sieci neuronowych odbywa się na zamkniętych zbiorach danych. Po ich przetworzeniu model nie aktualizuje wiedzy automatycznie.
Czy model językowy rozpozna nowe przepisy prawa?
Nie, jeśli weszły w życie po jego punkcie odcięcia wiedzy. Możesz jednak wprowadzić aktualne przepisy w treści pytania, aby model je zanalizował i wyciągnął wnioski na podstawie dostarczonych faktów.
W jaki sposób mogę sprawdzić, do kiedy model zna dane?
Producenci sztucznej inteligencji publikują w dokumentacji technicznej lub stopce narzędzia informacje o dacie knowledge cut-off. To najpewniejsze źródło określające zakres czasowy wiedzy modelu.
Czy sztuczna inteligencja sama wyszuka najnowsze informacje w sieci?
Tylko niektóre modele mają wbudowaną funkcję przeszukiwania internetu. Standardowe rozwiązania opierają się wyłącznie na danych zgromadzonych do punktu odcięcia wiedzy, więc nie zaktualizują treści samodzielnie.